技术文档收录
ASCII
Tcpdump
IPV4保留地址段
深入理解以太网网线原理 - 三帛的世界
白话 OSI 七层网络模型
Linux
WireGuard 一键安装脚本 | 秋水逸冰
SSH Config 那些你所知道和不知道的事 | Deepzz's Blog
Linux 让终端走代理的几种方法
ubuntu 20.04 server 版设置静态 IP 地址 - 链滴
Linux 挂载 Windows 共享磁盘的方法 - 技术学堂
将 SMB/CIFS 网络硬盘永久的挂载到 Ubuntu 上 - 简书
linux 获取当前脚本的绝对路径 | aimuke
[Linux] Linux 使用 / dev/urandom 生成随机数 - piaohua's blog
Linux 生成随机数的多种方法 | Just Do It
Linux 的 Centos7 版本下忘记 root 或者普通用户密码怎么办?
Git 强制拉取覆盖本地
SSH 安全加固指南 - FreeBuf 网络安全行业门户
Linux 系统安全强化指南 - FreeBuf 网络安全行业门户
Linux 入侵排查 - FreeBuf 网络安全行业门户
sshd_config 配置详解 - 简书
SSH 权限详解 - SegmentFault 思否
CentOS 安装 node.js 环境 - SegmentFault 思否
如何在 CentOS 7 上安装 Node.js 和 npm | myfreax
几款 ping tcping 工具总结
OpenVpn 搭建教程 | Jesse's home
openvpn 一键安装脚本 - 那片云
OpenVPN 解决 每小时断线一次 - 爱开源
OpenVPN 路由设置 – 凤曦的小窝
OpenVPN 设置非全局代理 - 镜子的记录簿
TinyProxy 使用帮助 - 简书
Ubuntu 下使用 TinyProxy 搭建代理 HTTP 服务器_Linux_运维开发网_运维开发技术经验分享
Linux 软件包管理工具 Snap 常用命令 - 简书
linux systemd 参数详解
Systemd 入门教程:命令篇 - 阮一峰的网络日志
记一次 Linux 木马清除过程
rtty:在任何地方通过 Web 访问您的终端
02 . Ansible 高级用法 (运维开发篇)
终于搞懂了服务器为啥产生大量的 TIME_WAIT!
巧妙的 Linux 命令,再来 6 个!
77% 的 Linux 运维都不懂的内核问题,这篇全告诉你了
运维工程师必备:请收好 Linux 网络命令集锦
一份阿里员工的 Java 问题排查工具单
肝了 15000 字性能调优系列专题(JVM、MySQL、Nginx and Tomcat),看不完先收
作业调度算法(FCFS,SJF,优先级调度,时间片轮转,多级反馈队列) | The Blog Of WaiterXiaoYY
看了这篇还不会 Linux 性能分析和优化,你来打我
2019 运维技能风向标
更安全的 rm 命令,保护重要数据
求你了,别再纠结线程池大小了!
Linux sudo 详解 | 失落的乐章
重启大法好!线上常见问题排查手册
sudo 使用 - 笨鸟教程的博客 | BY BenderFly
shell 在手分析服务器日志不愁? - SegmentFault 思否
sudo 与 visudo 的超细用法说明_陈发哥 007 的技术博客_51CTO 博客
ESXI 下无损扩展 Linux 硬盘空间 | Naonao Blog
Linux 学习记录:su 和 sudo | Juntao Tan 的个人博客
使用者身份切换 | Linux 系统教程(笔记)
你会使用 Linux 编辑器 vim 吗?
在 Windows、Linux 和 Mac 上查看 Wi-Fi 密码
linux 隐藏你的 crontab 后门 - 简书
Linux 定时任务详解 - Tr0y's Blog
linux 的 TCP 连接数量最大不能超过 65535 个吗,那服务器是如何应对百万千万的并发的?_一口 Linux 的博客 - CSDN 博客_tcp 连接数多少正常
万字长文 + 28 张图,一次性说清楚 TCP,运维必藏
为什么 p2p 模式的 tunnel 底层通常用 udp 而不是 tcp?
记一次服务器被入侵挖矿 - tlanyan
shell 判断一个变量是否为空方法总结 - 腾讯云开发者社区 - 腾讯云
系统安装包管理工具 | Escape
编译代码时动态地链接库 - 51CTO.COM
甲骨文 Oracle Cloud 添加新端口开放的方法 - WirelessLink 社区
腾讯云 Ubuntu 添加 swap 分区的方法_弓弧名家_玄真君的博客 - CSDN 博客
Oracle 开放全部端口并关闭防火墙 - 清~ 幽殇
谁再说不熟悉 Linux 命令, 就把这个给他扔过去!
即插即用,运维工程师必会正则表达式大全
Shell脚本编写及常见面试题
Samba 文件共享服务器
到底一台服务器上最多能创建多少个 TCP 连接 | plantegg
SSH 密钥登录 - SSH 教程 - 网道
在 Bash 中进行 encodeURIComponent/decodeURIComponent | Harttle Land
使用 Shell 脚本来处理 JSON - Tom CzHen's Blog
Docker
「Docker」 - 保存镜像 - 知乎
终于可以像使用 Docker 一样丝滑地使用 Containerd 了!
私有镜像仓库选型:Harbor VS Quay - 乐金明的博客 | Robin Blog
exec 与 entrypoint 使用脚本 | Mr.Cheng
Dockerfile 中的 CMD 与 ENTRYPOINT
使用 Docker 配置 MySQL 主从数据库 - 墨天轮
Alpine vs Distroless vs Busybox – 云原生实验室 - Kubernetes|Docker|Istio|Envoy|Hugo|Golang | 云原生
再见,Docker!
docker save 与 docker export 的区别 - jingsam
如何优雅的关闭容器
docker 储存之 tmpfs 、bind-mounts、volume | 陌小路的个人博客
Dockerfile 中 VOLUME 与 docker -v 的区别是什么 - 开发技术 - 亿速云
理解 docker 容器的退出码 | Vermouth | 博客 | docker | k8s | python | go | 开发
【Docker 那些事儿】容器监控系统,来自 Docker 的暴击_飞向星的客机的博客 - CSDN 博客
【云原生】Docker 镜像详细讲解_微枫 Micromaple 的博客 - CSDN 博客_registry-mirrors
【云原生】Helm 架构和基础语法详解
CMD 和 Entrypoint 命令使用变量的用法
实时查看容器日志 - 苏洋博客
Traefik 2 使用指南,愉悦的开发体验 - 苏洋博客
为你的 Python 应用选择一个最好的 Docker 映像 | 亚马逊 AWS 官方博客
【云原生】镜像构建实战操作(Dockerfile)
Docker Compose 中的 links 和 depends_on 的区别 - 编程知识 - 白鹭情
Python
Pipenv:新一代Python项目环境与依赖管理工具 - 知乎
Python list 列表实现栈和队列
Python 各种排序 | Lesley's blog
Python 中使用 dateutil 模块解析时间 - SegmentFault 思否
一个小破网站,居然比 Python 官网还牛逼
Python 打包 exe 的王炸 - Nuitka
Django - - 基础 - - Django ORM 常用查询语法及进阶
[Python] 小知識:== 和 is 的差異 - Clay-Technology World
Window
批处理中分割字符串 | 网络进行时
Windows 批处理基础命令学习 - 简书
在Windows上设置WireGuard
Windows LTSC、LTSB、Server 安装 Windows Store 应用商店
windows 重启 rdpclip.exe 的脚本
中间件
Nginx 中的 Rewrite 的重定向配置与实践
RabbitMQ 的监控
RabbitMq 最全的性能调优笔记 - SegmentFault 思否
为什么不建议生产用 Redis 主从模式?
高性能消息中间件——NATS
详解:Nginx 反代实现 Kibana 登录认证功能
分布式系统关注点:仅需这一篇,吃透 “负载均衡” 妥妥的
仅需这一篇,妥妥的吃透” 负载均衡”
基于 nginx 实现上游服务器动态自动上下线——不需 reload
Nginx 学习书单整理
最常见的日志收集架构(ELK Stack)
分布式之 elk 日志架构的演进
CAT 3.0 开源发布,支持多语言客户端及多项性能提升
Kafka 如何做到 1 秒处理 1500 万条消息?
Grafana 与 Kibana
ELK 日志系统之通用应用程序日志接入方案
ELK 简易 Nginx 日志系统搭建: ElasticSearch+Kibana+Filebeat
记一次 Redis 连接池问题引发的 RST
把 Redis 当作队列来用,你好大的胆子……
Redis 最佳实践:业务层面和运维层面优化
Redis 为什么变慢了?常见延迟问题定位与分析
好饭不怕晚,扒一下 Redis 配置文件的底 Ku
rabbitmq 集群搭建以及万级并发下的性能调优
别再问我 Redis 内存满了该怎么办了
Nginx 状态监控及日志分析
uWSGI 的安装及配置详解
uwsgi 异常服务器内存 cpu 爆满优化思路
Uwsgi 内存占用过多 - 简书
Nginx 的 limit 模块
Nginx 内置模块简介
Redis 忽然变慢了如何排查并解决?_redis_码哥字节_InfoQ 写作社区
领导:谁再用 redis 过期监听实现关闭订单,立马滚蛋!
Nginx 限制 IP 访问频率以及白名单配置_问轩博客
Nginx $remote_addr 和 $proxy_add_x_forwarded_for 变量详解
Caddy 部署实践
一文搞定 Nginx 限流
数据库
SqlServer 将数据库中的表复制到另一个数据库_MsSql_脚本之家
SQL Server 数据库同步,订阅、发布、复制、跨服务器
sql server 无法删除本地发布 | 辉克's Blog
SQLite全文检索
SQL 重复记录查询的几种方法 - 简书
SQL SERVER 使用订阅发布同步数据库(转)
Mysql 查看用户连接数配置及每个 IP 的请求情况 - 墨天轮
优化 SQL 的 21 条方案
SQL Server 连接时好时坏的奇怪问题
MS SQL 执行大脚本文件时,提示 “内存不足” 的解决办法 - 阿里云开发者社区
防火墙-iptables
iptables 常用规则:屏蔽 IP 地址、禁用 ping、协议设置、NAT 与转发、负载平衡、自定义链
防火墙 iptables 企业防火墙之 iptables
Linux 防火墙 ufw 简介
在 Ubuntu 中用 UFW 配置防火墙
在 Ubuntu20.04 上怎样使用 UFW 配置防火墙 - 技术库存网
监控类
开箱即用的 Prometheus 告警规则集
prometheus☞搭建 | zyh
docker 部署 Prometheus 监控服务器及容器并发送告警 | chris'wang
PromQL 常用命令 | LRF 成长记
prometheus 中使用 python 手写 webhook 完成告警
持续集成CI/CD
GitHub Actions 的应用场景 | 记录干杯
GithubActions · Mr.li's Blog
工具类
GitHub 中的开源网络广告杀手,十分钟快速提升网络性能
SSH-Auditor:一款 SHH 弱密码探测工具
别再找了,Github 热门开源富文本编辑器,最实用的都在这里了 - srcmini
我最喜欢的 CLI 工具
推荐几款 Redis 可视化工具
内网代理工具与检测方法研究
环境篇:数据同步工具 DataX
全能系统监控工具 dstat
常用 Web 安全扫描工具合集
给你一款利器!轻松生成 Nginx 配置文件
教程类
Centos7 搭建神器 openvpn | 运维随笔
搭建 umami 收集个人网站统计数据 | Reorx’s Forge
openvpn安装教程
基于 gitea+drone 完成小团队的 CI/CD - 德国粗茶淡饭
将颜色应用于交替行或列
VMware Workstation 全系列合集 精简安装注册版 支持 SLIC2.6、MSDM、OSX 更新 16.2.3_虚拟机讨论区_安全区 卡饭论坛 - 互助分享 - 大气谦和!
在 OpenVPN 上启用 AD+Google Authenticator 认证 | 运维烂笔头
Github 进行 fork 后如何与原仓库同步:重新 fork 很省事,但不如反复练习版本合并 · Issue #67 · selfteaching/the-craft-of-selfteaching
卧槽,VPN 又断开了!!- 阿里云开发者社区
Grafana Loki 学习之踩坑记
zerotier 的 planet 服务器(根服务器)的搭建踩坑记。无需 zerotier 官网账号。
阿里云 qcow2 镜像转 vmdk,导入 ESXi - 唐际忠的博客
Caddy 入门 – 又见杜梨树
【Caddy2】最新 Caddy2 配置文件解析 - Billyme 的博客
Web 服务器 Caddy 2 | Haven200
手把手教你打造高效的 Kubernetes 命令行终端
Keras 作者:给软件开发者的 33 条黄金法则
超详细的网络抓包神器 Tcpdump 使用指南
使用 fail2ban 和 FirewallD 黑名单保护你的系统
linux 下 mysql 数据库单向同步配置方法分享 (Mysql)
MySQL 快速删除大量数据(千万级别)的几种实践方案
GitHub 上的优质 Linux 开源项目,真滴牛逼!
WireGuard 教程:使用 Netmaker 来管理 WireGuard 的配置 – 云原生实验室 - Kubernetes|Docker|Istio|Envoy|Hugo|Golang | 云原生
Tailscale 基础教程:Headscale 的部署方法和使用教程 – 云原生实验室 - Kubernetes|Docker|Istio|Envoy|Hugo|Golang | 云原生
Nebula Graph 的 Ansible 实践
改进你的 Ansible 剧本的 4 行代码
Caddy 2 快速简单安装配置教程 – 高玩梁的博客
切换至 Caddy2 | 某不科学的博客
Caddy2 简明教程 - bleem
树莓派安装 OpenWrt 突破校园网限制 | Asttear's Blog
OpenVPN 路由设置 – 凤曦的小窝
个性化编译 LEDE 固件
盘点各种 Windows/Office 激活工具
[VirtualBox] 1、NAT 模式下端口映射
VirtualBox 虚拟机安装 openwrt 供本机使用
NUC 折腾笔记 - 安装 ESXi 7 - 苏洋博客
锐捷、赛尔认证 MentoHUST - Ubuntu 中文
How Do I Use A Client Certificate And Private Key From The IOS Keychain? | OpenVPN
比特记事簿: 笔记: 使用电信 TR069 内网架设 WireGuard 隧道异地组网
利用 GitHub API 获取最新 Releases 的版本号 | 这是只兔子
docsify - 生成文档网站简单使用教程 - SegmentFault 思否
【干货】Chrome 插件 (扩展) 开发全攻略 - 好记的博客
一看就会的 GitHub 骚操作,让你看上去像一位开源大佬
【计算机网络】了解内网、外网、宽带、带宽、流量、网速_墩墩分墩 - CSDN 博客
mac-ssh 配置 | Sail
如何科学管理你的密码
VirtualBox NAT 端口映射实现宿主机与虚拟机相互通信 | Shao Guoliang 的博客
CentOS7 配置网卡为静态 IP,如果你还学不会那真的没有办法了!
laisky-blog: 近期折腾 tailscale 的一些心得
使用 acme.sh 给 Nginx 安装 Let’ s Encrypt 提供的免费 SSL 证书 · Ruby China
acme 申请 Let’s Encrypt 泛域名 SSL 证书
从 nginx 迁移到 caddy
使用 Caddy 替代 Nginx,全站升级 https,配置更加简单 - Diamond-Blog
http.proxy - Caddy 中文文档
动手撸个 Caddy(二)| Caddy 命令行参数最全教程 | 飞雪无情的总结
Caddy | 学习笔记 - ijayer
Caddy 代理 SpringBoot Fatjar 应用上传静态资源
使用 graylog3.0 收集 open××× 日志进行审计_年轻人,少吐槽,多搬砖的技术博客_51CTO 博客
提高国内访问 github 速度的 9 种方法! - SegmentFault 思否
VM16 安装 macOS 全网最详细
2022 目前三种有效加速国内 Github
How to install MariaDB on Alpine Linux | LibreByte
局域网内电脑 - ipad 文件共享的三种方法 | 岚
多机共享键鼠软件横向测评 - 尚弟的小笔记
VLOG | ESXI 如何升级到最新版,无论是 6.5 还是 6.7 版本都可以顺滑升级。 – Vedio Talk - VLOG、科技、生活、乐分享
远程修改 ESXi 6.7 管理 IP 地址 - 腾讯云开发者社区 - 腾讯云
几乎不要钱自制远程 PLC 路由器方案
traefik 简易入门 | 个人服务器运维指南 | 山月行
更完善的 Docker + Traefik 使用方案 - 苏洋博客
MicroSD·TF 卡终极探秘 ·MLC 颗粒之谜 1 三星篇_microSD 存储卡_什么值得买
macOS 绕过公证和应用签名方法 - 走客
MiscSecNotes / 内网端口转发及穿透. md at master · JnuSimba/MiscSecNotes
我有特别的 DNS 配置和使用技巧 | Sukka's Blog
SEO:初学者完整指南
通过 OpenVPN 实现流量审计
OpenVPN-HOWTO
OpenVPN Server · Devops Roadmap
Linux 运维必备的 13 款实用工具, 拿好了~
linux 平台下 Tomcat 的安装与优化
Linux 运维跳槽必备的 40 道面试精华题
Bash 脚本进阶,经典用法及其案例 - alonghub - 博客园
推荐几个非常不错的富文本编辑器 - 走看看
在 JS 文件中加载 JS 文件的方法 - 月光博客
#JavaScript 根据需要动态加载脚本并设置自定义参数
笔记本电脑 BIOS 修改及刷写教程
跨平台加密 DNS 和广告过滤 personalDNSfilter · LinuxTOY
AdGuard Home 安装及使用指北
通过 Amazon S3 协议挂载 OSS
记一次云主机如何挂载对象存储
(续)acme.sh 脚本使用新 cloudflare api 令牌申请证书 - 世界你好
本文档发布于https://mrdoc.fun
-
+
首頁
万字长文 + 28 张图,一次性说清楚 TCP,运维必藏
> 本文由 [简悦 SimpRead](http://ksria.com/simpread/) 转码, 原文地址 [mp.weixin.qq.com](https://mp.weixin.qq.com/s/jYRITH_hpVkPPK1mjOQjtQ)  做 IT 相关的工作,肯定都离不开网络,网络中最重要的协议是 TCP。无论是实际工作还是笔试面试,你看哪里能少得了 TCP? 我看过 RFC 中与 TCP 相关的文档,也看过 linux 中 TCP 相关的源码,也看过不少框架中的 TCP 相关的代码,对 TCP 是有点感觉了。 一直想找个时间来分享下 TCP 相关的知识,如果大家有疑问,欢迎相互交流。其实,搞透了 TCP 之后,发现它也就那么回事。 考虑最简单的情况:两台主机之间的通信。这个时候只需要一条网线把两者连起来,规定好彼此的硬件接口,如都用 USB、电压 10v、频率 2.4GHz 等,**这一层就是物理层,这些规定就是物理层协议** 。  我们当然不满足于只有两台电脑连接,因此我们可以使用交换机把多个电脑连接起来,如下图: 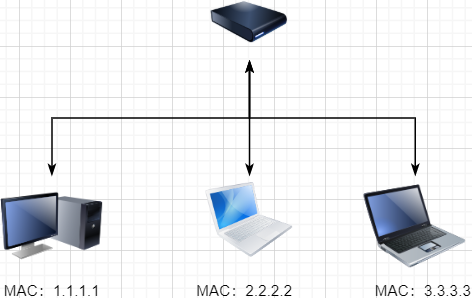 这样连接起来的网络,称为局域网,也可以称为以太网(以太网是局域网的一种)。在这个网络中,我们需要标识每个机器,这样才可以指定要和哪个机器通信。这个标识就是硬件地址 MAC。硬件地址随机器的生产就被确定,永久性唯一。在局域网中,我们需要和另外的机器通信时,只需要知道他的硬件地址,交换机就会把我们的消息发送到对应的机器。 这里我们可以不管底层的网线接口如何发送,把物理层抽离,在他之上创建一个新的层次,这就是**数据链路层** 。 我们依然不满足于局域网的规模,需要把所有的局域网联系起来,这个时候就需要用到路由器来连接两个局域网: 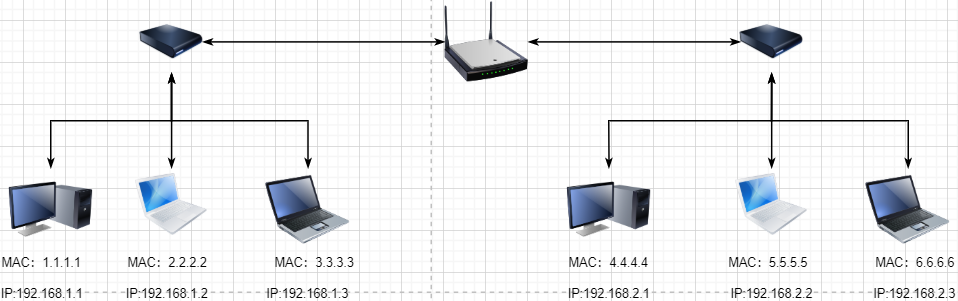 但是如果我们还是使用硬件地址来作为通信对象的唯一标识,那么当网络规模越来越大,需要记住所有机器的硬件地址是不现实的;同时,一个网络对象可能会频繁更换设备,这个时候硬件地址表维护起来更加复杂。这里使用了一个新的地址来标记一个网络对象:**IP 地址** 。 通过一个简单的寄信例子来理解 IP 地址。 我住在北京市,我朋友 A 住在上海市,我要给朋友 A 写信: 1. 写完信,我会在信上写好我朋友 A 的地址,并放到北京市邮局(给信息附加目标 IP 地址,并发送给路由器) 2. 邮局会帮我把信运输到上海市当地邮局(信息会经过路由传递到目标 IP 局域网的路由器) 3. 上海市当地路由器会帮我把信交给朋友 A(局域网内通信) 因此,这里 IP 地址就是一个网络接入地址(朋友 A 的住址),我只需要知道目标 IP 地址,路由器就可以把消息给我带到。**在局域网中,就可以动态维护一个 MAC 地址与 IP 地址的映射关系,根据目的 IP 地址就可以寻找到机器的 MAC 地址进行发送** 。 这样我们不需管理底层如何去选择机器,我们只需要知道 IP 地址,就可以和我们的目标进行通信。这一层就是**网络层**。网络层的核心作用就是 **提供主机之间的逻辑通信** 。这样,在网络中的所有主机,在逻辑上都连接起来了,上层只需要提供目标 IP 地址和数据,网络层就可以把消息发送到对应的主机。 一个主机有多个进程,进程之间进行不同的网络通信,如边和朋友开黑边和女朋友聊微信。我的手机同时和两个不同机器进行通信。那么当我的手机收到数据时,如何区分是微信的数据,还是王者的数据?那么就必须在网络层之上再添加一层:**运输层** : 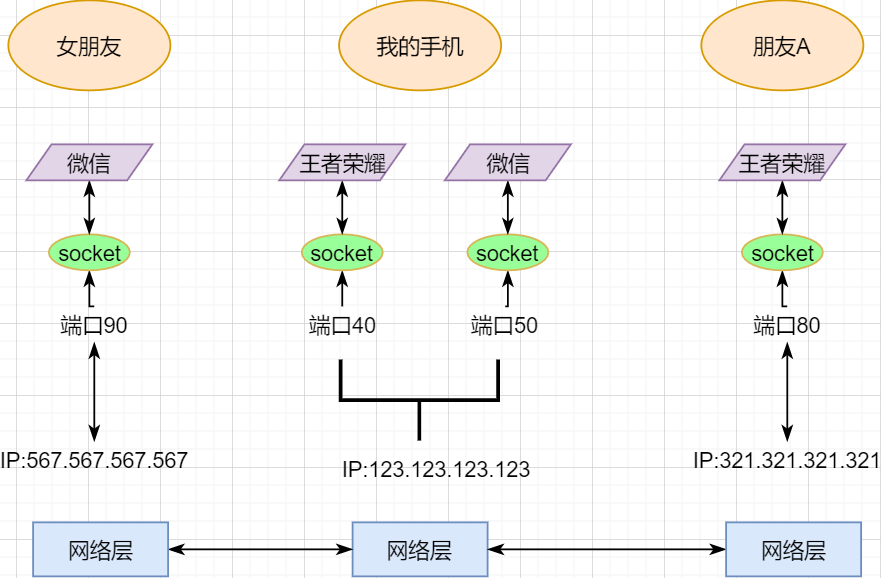 运输层通过 socket(套接字),将网络信息进行进一步的拆分,不同的应用进程可以独立进行网络请求,互不干扰。这就是运输层的最本质特点:**提供进程之间的逻辑通信** 。这里的进程可以是主机之间,也可以是同个主机,所以在 android 中,socket 通信也是进程通信的一种方式。 现在不同的机器上的应用进程之间可以独立通信了,那么我们就可以在计算机网络上开发出形形式式的应用:如 web 网页的 http,文件传输 ftp 等等。这一层称为**应用层**。 应用层还可以进一步拆分出表示层、会话层,但他们的本质特点都没有改变:**完成具体的业务需求** 。和下面的四层相比,他们并不是必须的,可以归属到应用层中。 最后对计网分层进行小结: 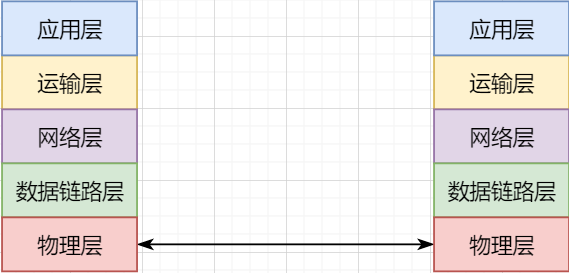 1. 最底层物理层,负责两个机器之间通过硬件的直接通信; 2. 数据链路层使用硬件地址在局域网中进行寻址,实现局域网通信; 3. 网络层通过抽象 IP 地址实现主机之间的逻辑通信; 4. 运输层在网络层的基础上,对数据进行拆分,实现应用进程的独立网络通信; 5. 应用层在运输层的基础上,根据具体的需求开发形形式式的功能。 这里需要注意的是,分层并不是在物理上的分层,而是逻辑上的分层。通过对底层逻辑的封装,使得上层的开发可以直接依赖底层的功能而无需理会具体的实现,简便了开发。 这种分层的思路,也就是责任链设计模式,通过层层封装,把不同的职责独立起来,更加方便开发、维护等等。okHttp 中的拦截器设计模式,也是这种责任链模式。 / 运输层 / 本文主要是讲解 TCP,这里需要增加一些运输层的知识。 #### **本质:提供进程通信** 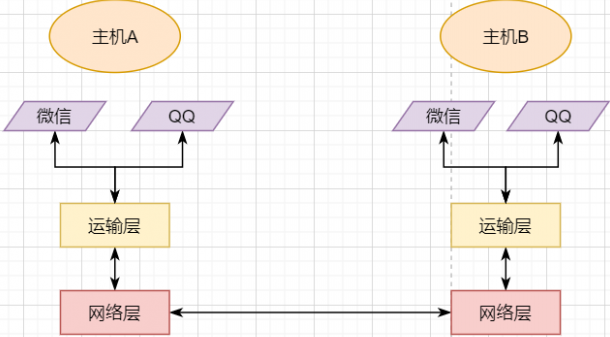 在运输层之下的网络层,是不知道该数据包属于哪个进程,他只负责数据包的接收与发送。运输层则负责接收不同进程的数据交给网络层,同时把网络层的数据拆分交给不同的进程。从上往下汇聚到网络层,称为**多路复用**,从下往上拆分,称为**多路拆分** 。 运输层的表现,受网络层的限制。这很好理解,网络层是运输层的底层支持。所以运输层是无法决定自己带宽、时延等的上限。但可以基于网络层开发更多的特性:如可靠传输。网络层只负责尽力把数据包从一端发送到另一端,而不保证数据可以到达且完整。 #### **底层实现:socket** 前面讲到,最简单的运输层协议,就是提供进程之间的独立通信 ,但底层的实现,是 **socket 之间的独立通信** 。在网络层中,IP 地址是一个主机逻辑地址,而在运输层中,socket 是一个进程的逻辑地址;当然,一个进程可以拥有多个 socket。应用进程可以通过监听 socket,来获取这个 socket 接受到的消息。 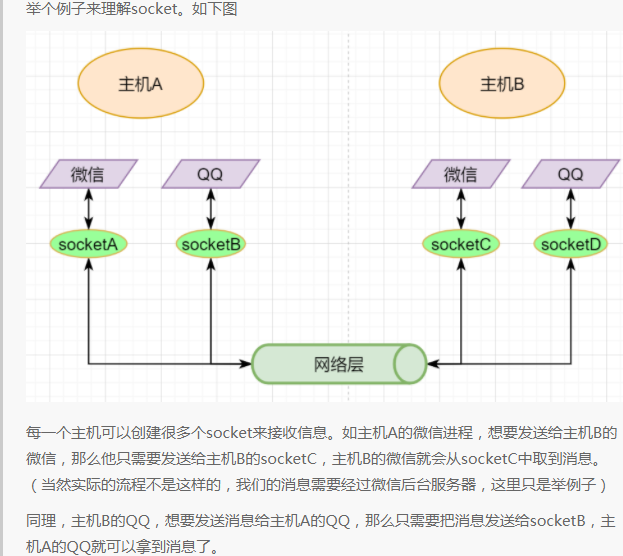 socket 并不是一个实实在在的东西,而是运输层抽象出来的一个对象。运输层增加了**端口**这个概念,来区分不同的 socket。端口可以理解为一个主机上有很多的网络通信口,每个端口都有一个端口号,端口的数量由运输层协议确定。 不同的运输层协议对 socket 有不同的定义方式。在 UDP 协议中,使用目标 IP + 目标端口号来定义一个 socket;在 TCP 中使用目标 IP + 目标端口号 + 源 IP + 源端口号来定义一个 socket。我们只需要在运输层报文的头部附加上这些信息,目标主机就会知道我们要发送给哪个 socket,对应监听该 socket 的进程就可获得信息。 #### **运输层协议** 运输层的协议就是大名鼎鼎的 TCP 和 UDP。其中,UDP 是最精简的运输层协议,只实现了进程间的通信;而 TCP 在 UDP 的基础上,实现了可靠传输、流量控制、拥塞控制、面向连接等等特性,同时也更加复杂。 当然除此之外,还有更多更优秀的运输层协议,但目前广为使用的,就是 TCP 和 UDP。UDP 在后面也会总结到。 / TCP 协议首部 / TCP 协议,表现在报文上,就是会在应用层传输下来的数据前附加上一个 TCP 首部,这个首部附加了 TCP 信息,先来整体看一下这个首部的结构: 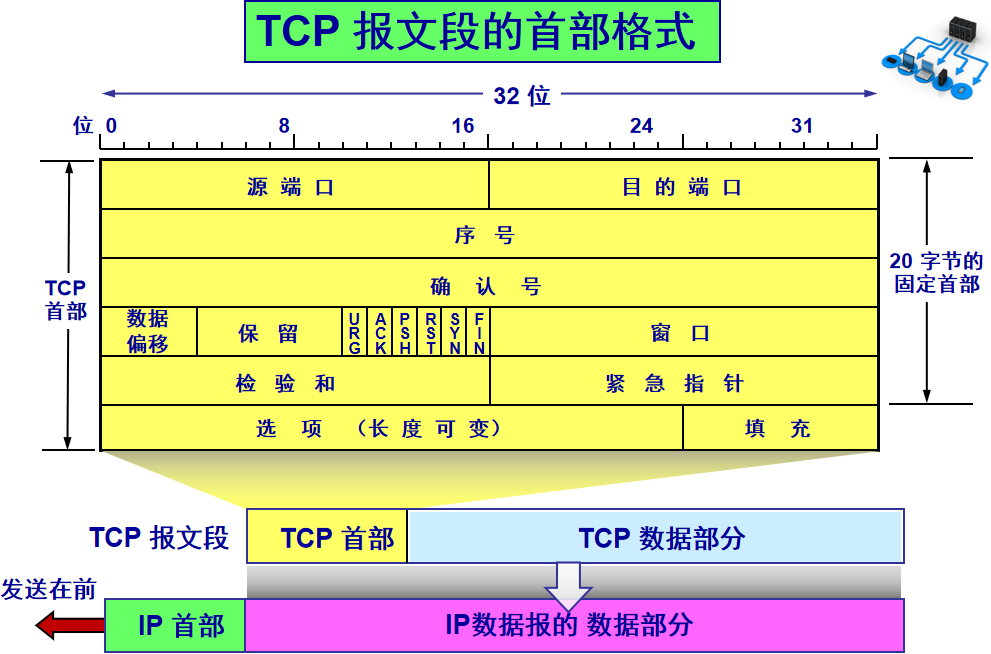 这张图是来自一位大学老师的课件, 非常好用,所以一直拿来学习。最下面部分表示了报文之间的关系,TCP 数据部分就是应用层传下来的数据。 TCP 首部固定长度是 20 字节,下面还有 4 字节是可选的。内容很多,但其中有一些我们比较熟悉的:源端口,目标端口。嗯?socket 不是还需要 IP 进行定位吗?IP 地址在网络层被附加了。其他的内容后面都会慢慢讲解,作为一篇总结文章,这里放出查阅表,方便复习: 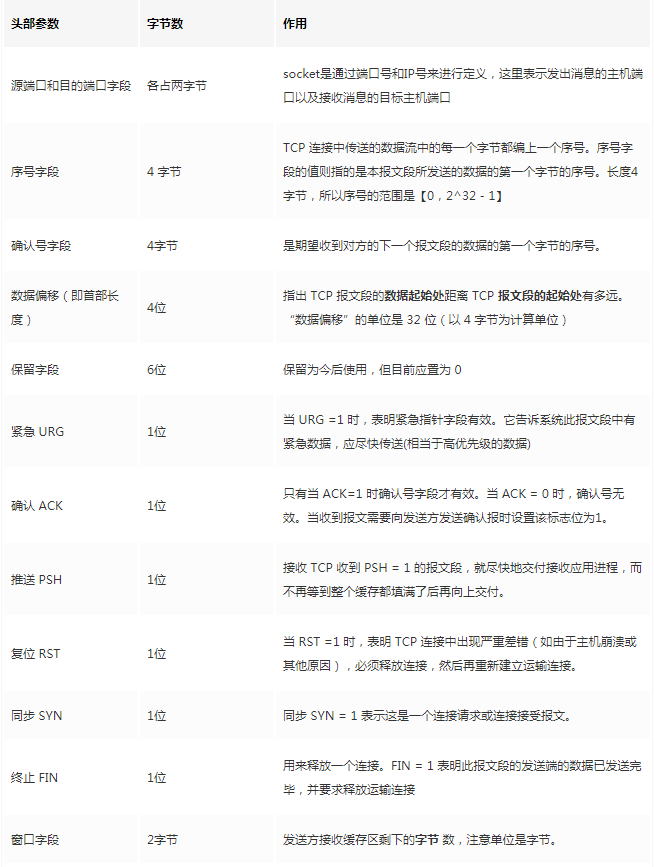 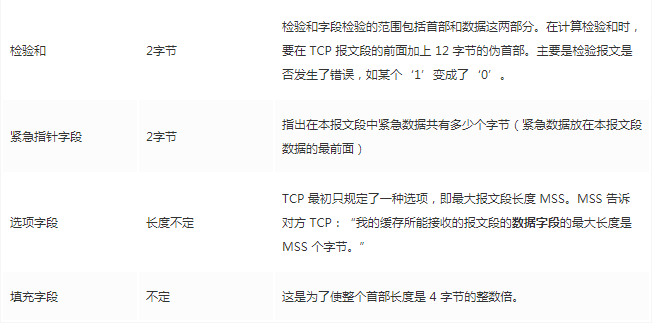 选项字段中包含以下其他选项:  讲完下面内容,再回来看这些字段就熟悉了。 / TCP 面向字节流特性 / TCP 并不是把应用层传输过来的数据直接加上首部然后发送给目标,而是把数据看成一个字节 流,给他们标上序号之后分部分发送。这就是 TCP 的 **面向字节流** 特性: 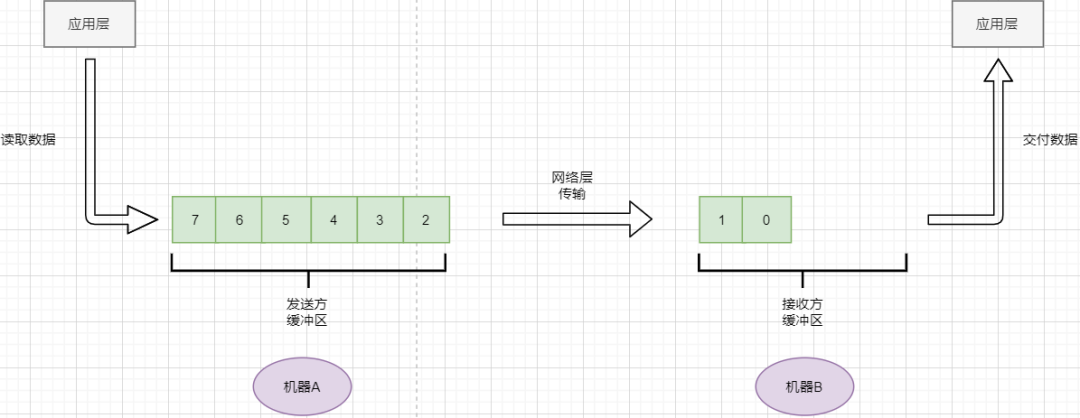 * TCP 会以流的形式从应用层读取数据并存放在自己的发送缓存区中,同时为这些**字节**标上序号 * TCP 会从发送方缓冲区选择适量的字节组成 TCP 报文,通过网络层发送给目标 * 目标会读取字节并存放在自己的接收方缓冲区中,并在合适的时候交付给应用层 面向字节流的好处是无需一次存储过大的数据占用太多内存,坏处是无法知道这些字节代表的意义,例如应用层发送一个音频文件和一个文本文件,对于 TCP 来说就是一串字节流,没有意义可言,这会导致粘包以及拆包问题,后面讲。 / 可靠传输原理 / 前面讲到,TCP 是可靠传输协议,也就是,一个数据交给他,他肯定可以完整无误地发送到目标地址,除非网络炸了。他实现的网络模型如下: 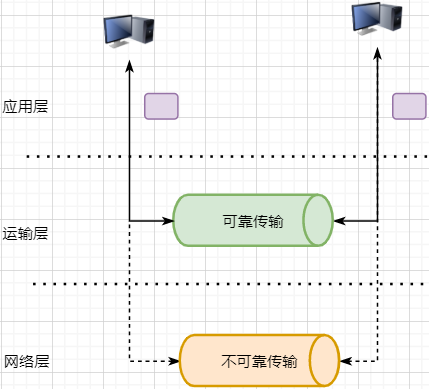 对于应用层来说,他就是一个可靠传输的底层支持服务;而运输层底层采用了网络层的不可靠传输。虽然在网络层甚至数据链路层就可以使用协议来保证数据传输的可靠性,但这样网络的设计会更加复杂、效率会随之降低。把数据传输的可靠性保证放在运输层,会更加合适。 可靠传输原理的重点总结一下有:**滑动窗口、超时重传、累积确认、选择确认、连续 ARQ** 。 #### **停止等待协议** 要实现可靠传输,最简便的方法就是:我发送一个数据包给你,然后你跟我回复收到,我继续发送下一个数据包。传输模型如下: 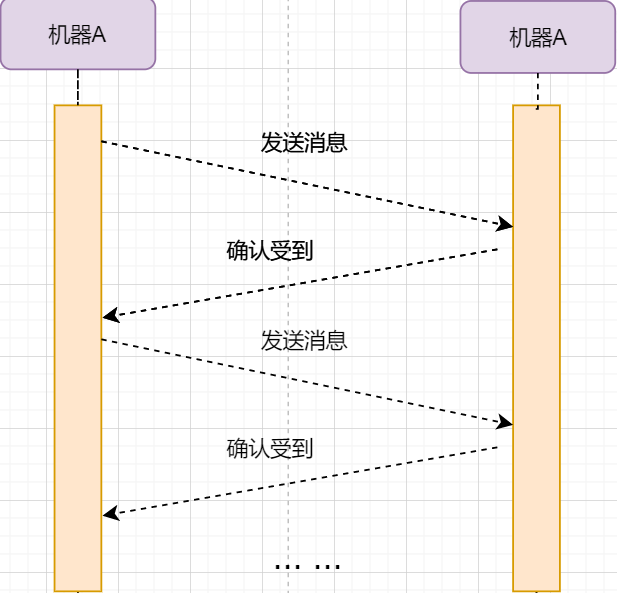 这种 “一来一去” 的方法来保证传输可靠就是**停止等待协议**(stop-and-wait)。不知道还记不记得前面 TCP 首部有一个 ack 字段,当他设置为 1 的时候,表示这个报文是一个确认收到报文。 然后再来考虑一种情况:丢包。网络环境不可靠,导致每一次发送的数据包可能会丢失,如果机器 A 发送了数据包丢失了,那么机器 B 永远接收不到数据,机器 A 永远在等待。解决这个问题的方法是:**超时重传** 。当机器 A 发出一个数据包时便开始计时,时间到还没收到确认回复,就可以认为是发生了丢包,便再次发送,也就是重传。 但重传会导致另一种问题:如果原先的数据包并没有丢失,只是在网络中待的时间比较久,这个时候机器 B 会受到两个数据包,那么机器 B 是如何辨别这两个数据包是属于同一份数据还是不同的数据?这就需要前面讲过的方法:**给数据字节进行编号**。这样接收方就可以根据数据的字节编号,得出这些数据是接下来的数据,还是重传的数据。 在 TCP 首部有两个字段:序号和确认号,他们表示发送方数据第一个字节的编号,和接收方期待的下一份数据的第一个字节的编号。前面讲到 TCP 是面向字节流,但是他并不是一个字节一个字节地发送,而是一次截取一整段。截取的长度受多种因素影响,如缓存区的数据大小、数据链路层限制的帧大小等。 #### **连续 ARQ 协议** 停止等待协议已经可以满足可靠传输了,但有一个致命缺点:**效率太低**。发送方发送一个数据包之后便进入等待,这个期间并没有干任何事,浪费了资源。解决的方法是:**连续发送数据包**。模型如下: 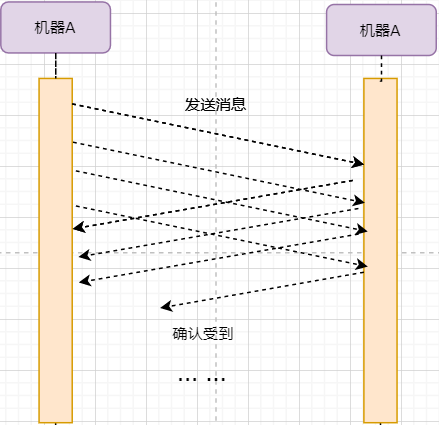 和停止等待最大的不同就是,他会源源不断地发送,接收方源源不断收到数据之后,逐一进行确认回复。这样便极大地提高了效率。但同样,带来了一些额外的问题: 发送是否可以无限发送直到把缓冲区所有数据发送完?不可以。因为需要考虑接收方缓冲区以及读取数据的能力。如果发送太快导致接收方无法接受,那么只是会频繁进行重传,浪费了网络资源。所以发送方发送数据的范围,需要考虑到接收方缓冲区的情况。这就是 TCP 的**流量控制** 。解决方法是:**滑动窗口** 。基本模型如下: 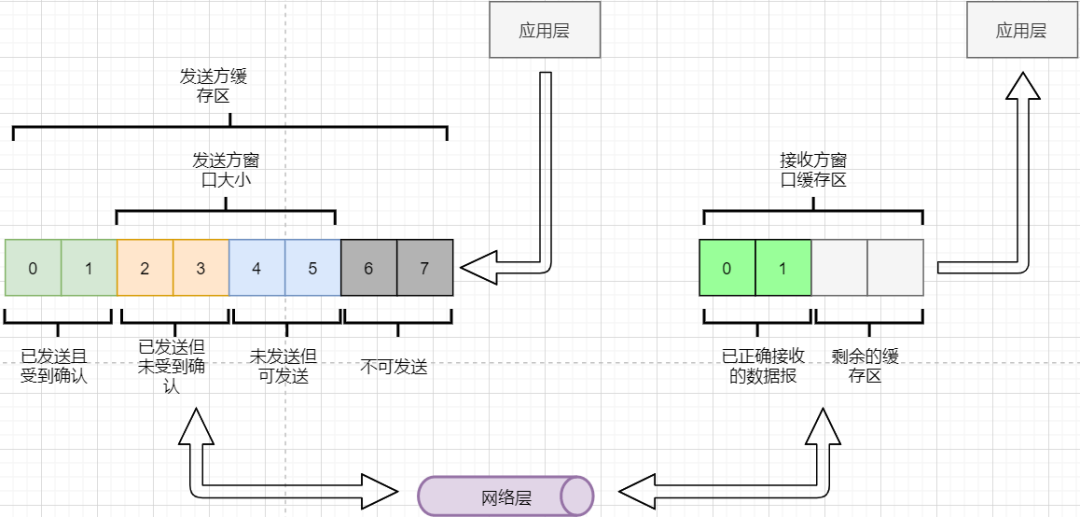 * 发送方需要根据接收方的缓冲区大小,设置自己的可发送窗口大小,处于窗口内的数据表示可发送,之外的数据不可发送。 * 当窗口内的数据接收到确认回复时,整个窗口会往前移动,直到发送完成所有的数据 在 TCP 的首部有一个窗口大小字段,他表示接收方的剩余缓冲区大小,让发送方可以调整自己的发送窗口大小。通过滑动窗口,就可以实现 TCP 的流量控制,不至于发送太快,导致太多的数据丢失。 连续 ARQ 带来的第二个问题是:网络中充斥着和发送数据包一样数据量的确认回复报文,因为每一个发送数据包,必须得有一个确认回复。提高网络效率的方法是:**累积确认** 。接收方不需要逐个进行回复,而是累积到一定量的数据包之后,告诉发送方,在此数据包之前的数据全都收到。例如,收到 1234,接收方只需要告诉发送方我收到 4 了,那么发送方就知道 1234 都收到了。 第三个问题是:如何处理丢包情况。在停止等待协议中很简单,直接一个超时重传就解决了。但,连续 ARQ 中不太一样。例如:接收方收到了 123 567,六个字节,编号为 4 的字节丢失了。按照累积确认的思路,只能发送 3 的确认回复,567 都必须丢掉,因为发送方会进行重传。这就是 **GBN(go-back-n)** 思路。 但是我们会发现,只需要重传 4 即可,这样不是很浪费资源,所以就有了:**选择确认 SACK** 。在 TCP 报文的选项字段,可以设置已经收到的报文段,每一个报文段需要两个边界来进行确定。这样发送方,就可以根据这个选项字段只重传丢失的数据了。 #### **可靠传输小结** 到这里关于 TCP 的可靠传输原理就已经介绍的差不多。最后进行一个小结: * 通过连续 ARQ 协议与发送 - 确认回复模式来保证每一个数据包都到达接收方 * 通过给字节编号的方法,来标记每一个数据是属于重传还是新的数据 * 通过超时重传的方式,来解决数据包在网络中丢失的问题 * 通过滑动窗口来实现流量控制 * 通过累积确认 + 选择确认的方法来提高确认回复与重传的效率 当然,这只是可靠传输的冰山一角,感兴趣可以再深入去研究(和面试官聊天已经差不多了 [狗头])。 / 拥塞控制 / 拥塞控制考虑的是另外一个问题:**避免网络过分拥挤导致丢包严重,网络效率降低 。** 拿现实的交通举例子: 高速公路同一时间可通行的汽车数量是一定的,当节假日时,就会发生严重的堵车。在 TCP 中,数据包超时,会进行重传,也就是会进来更多的汽车,这时候更堵,最后导致的结果就是:丢包 - 重传 - 丢包 - 重传。最后整个网络瘫痪了。 这里的拥塞控制和前面的流量控制不是一个东西,流量控制是拥塞控制的手段:为了避免拥塞,必须对流量进行控制。拥塞控制目的是:限制每个主机的发送的数据量,避免网络拥塞效率下降。就像广州等地,限制车牌号出行是一个道理。不然大家都堵在路上,谁都别想走。 拥塞控制的解决方法是流量控制,流量控制的实现是滑动窗口,所以**拥塞控制最终也是通过限制发送方的滑动窗口大小来限制流量** 。当然,拥塞控制的手段不只是流量控制,导致拥塞的因素有:路由器缓存、带宽、处理器处理速度等等。提升硬件能力(把 4 车道改成 8 车道)是其中一个方法,但毕竟硬件提升是有瓶颈的,没办法不断提升,还是需要从 tcp 本身来增加算法,解决拥塞。 拥塞控制的重点有 4 个:**慢开始、快恢复、快重传、拥塞避免**。这里依旧献祭出大学老师的 ppt 图片: 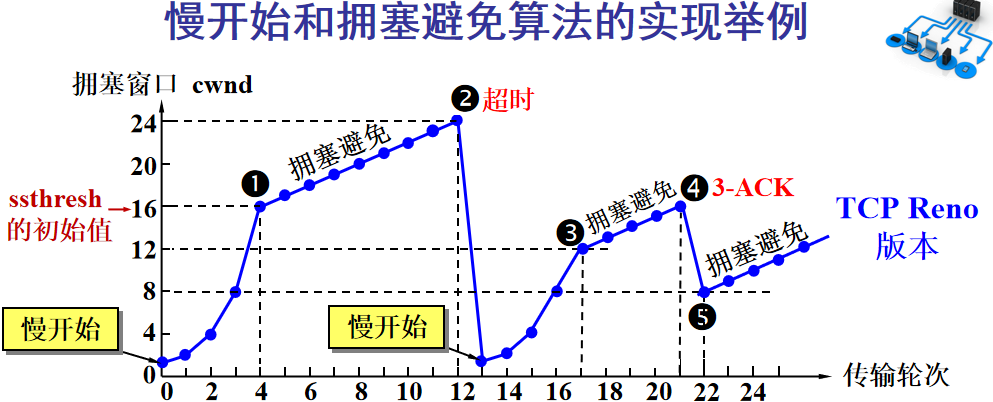 Y 轴表示的是发送方窗口大小,X 轴表示的是发送的轮次(不是字节编号)。 * 最开始的时候,会把窗口设置一个较小的值,然后每轮变为原来的两倍。这是慢开始。 * 当窗口值到达 ssthresh 值,这个值是需要通过实时网络情况设置的一个窗口限制值,开始进入拥塞避免,每轮把窗口值提升 1,慢慢试探网络的底线。 * 如果发生了数据超时,表示极可能发生了拥塞,然后回到慢开始,重复上面的步骤。 * 如果收到三个相同的确认回复,表示现在网络的情况不太好,把 ssthresh 的值设置为原来的一半,继续拥塞避免。这部分称为快恢复。 * 如果收到丢包信息,应该尽快把丢失的包重传一次,这是快重传。 * 当然,窗口的最终上限是不能无限上涨的,他不能超过接收方的缓存区大小。 通过这个算法,就可以在很大程度上,避免网络拥挤。 除此之外,还可以让路由器在缓存即将满的时候,告知发送方我快满了,而不是等到出现了超时再进行处理,这是**主动队列管理 AQM**。此外还有很多方法,但是上面的算法是重点。 / 面向连接 / 这一小节讲的就是无人不晓的 TCP 三次握手与四次挥手这些,经过前面的内容,这一小节其实已经很好理解。 TCP 是面向连接的,那连接是什么?**这里的连接并不是实实在在的连接,而是通信双方彼此之间的一个记录** 。TCP 是一个全双工通信,也就是可以互相发送数据,所以双方都需要记录对方的信息。根据前面的可靠传输原理,TCP 通信双方需要为对方准备一个接收缓冲区可以接收对方的数据、记住对方的 socket 知道怎么发送数据、记住对方的缓冲区来调整自己的窗口大小等等,这些记录,就是一个连接。 在运输层小节中讲到,运输层双方通信的地址是采用 socket 来定义的,TCP 也不例外。TCP 的每一个连接只能有两个对象,也就是两个 socket,而不能有三个。所以 socket 的定义需要源 IP、源端口号、目标 IP、目标端口号四个关键因素,才不会发生混乱。 假如 TCP 和 UDP 一样只采用目标 IP + 目标端口号来定义 socket,那么就会出现多个发送方同时发送到同一个目标 socket 的情况。这个时候 TCP 无法区分这些数据是否来自不同的发送方,就会导致出现错误。 既然是连接,就有两个关键要点:建立连接、断开连接。 #### **建立连接** 建立连接的目的就是交换彼此的信息,然后记住对方的信息。所以双方都需要发送彼此的信息给对方: 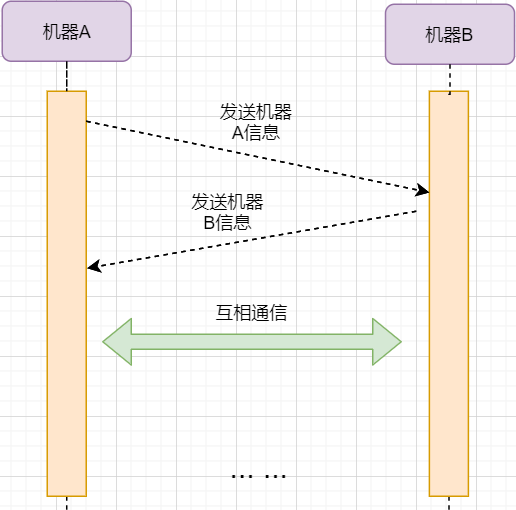 但前面的可靠传输原理告诉我们,数据在网络中传输是不可靠的,需要对方给予我们一个确认回复,才可以保证消息正确到达。如下图: 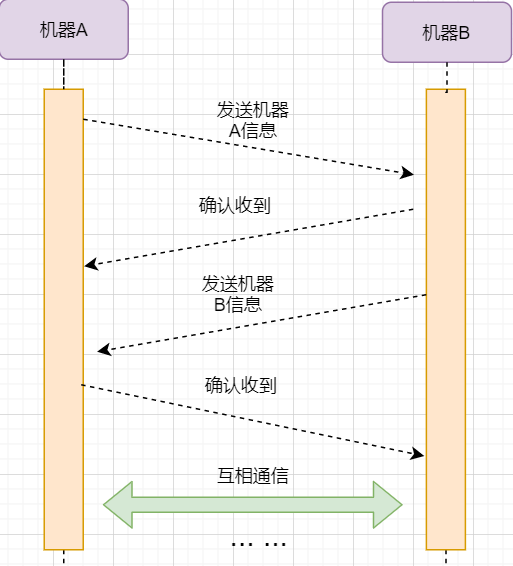 机器 B 的确认收到和机器 B 信息可以进行合并,减少次数;而且发送机器 B 给机器 A 本身就代表了机器 B 已经收到了消息,所以最后的示例图是: 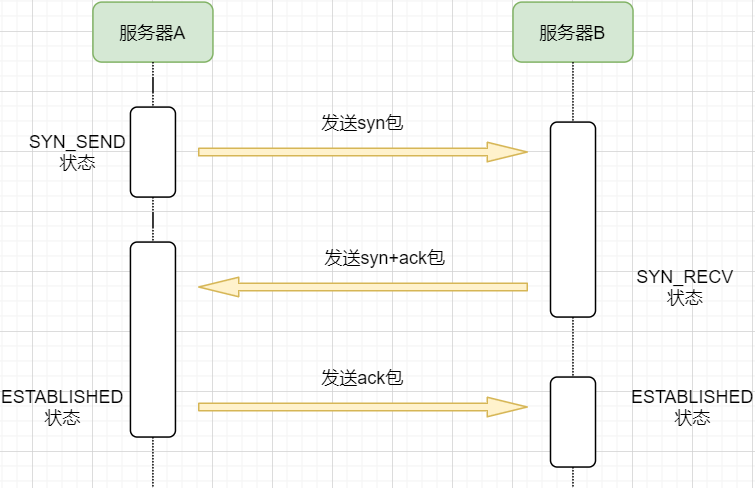 步骤如下: 1. 机器 A 发送 syn 包向机器 B 请求建立 TCP 连接,并附加上自身的接收缓冲区信息等,机器 A 进入 SYN_SEND 状态,表示请求已经发送正在等待回复; 2. 机器 B 收到请求之后,根据机器 A 的信息记录下来,并创建自身的接收缓存区,向机器 A 发送 syn+ack 的合成包,同时自身进入 SYN_RECV 状态,表示已经准备好了,等待机器 A 的回复就可以向 A 发送数据; 3. 机器 A 收到回复之后记录机器 B 的信息,发送 ack 信息,自身进入 ESTABLISHED 状态,表示已经完全准备好了,可以进行发送和接收; 4. 机器 B 收到 ACK 数据之后,进入 ESTABLISHED 状态。 三次消息的发送,称为三次握手。 #### **断开连接** 断开连接和三次握手类似,直接上图: 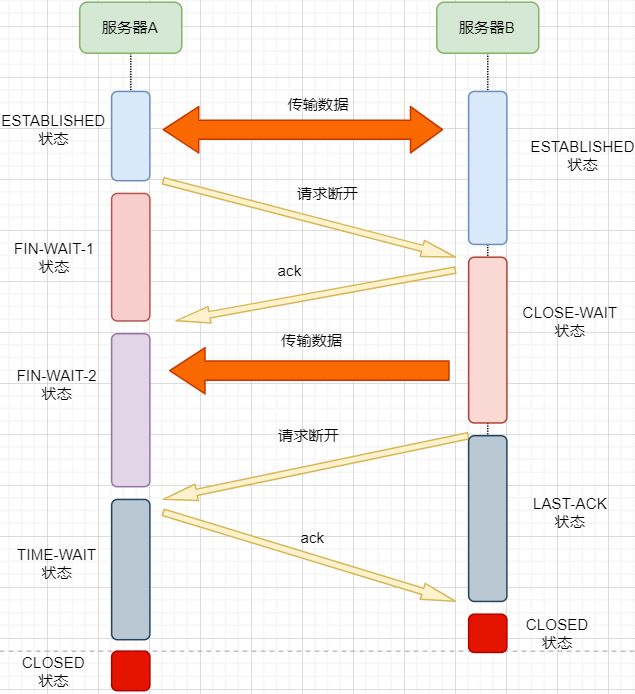 1. 机器 A 发送完数据之后,向机器 B 请求断开连接,自身进入 FIN_WAIT_1 状态,表示数据发送完成且已经发送 FIN 包(FIN 标志位为 1); 2. 机器 B 收到 FIN 包之后,回复 ack 包表示已经收到,但此时机器 B 可能还有数据没发送完成,自身进入 CLOSE_WAIT 状态,表示对方已发送完成且请求关闭连接,自身发送完成之后可以关闭连接; 3. 机器 B 数据发送完成之后,发送 FIN 包给机器 B ,自身进入 LAST_ACK 状态,表示等待一个 ACK 包即可关闭连接; 4. 机器 A 收到 FIN 包之后,知道机器 B 也发送完成了,回复一个 ACK 包,并进入 TIME_WAIT 状态 _TIME_WAIT 状态比较特殊。当机器 A 收到机器 B 的 FIN 包时,理想状态下,确实是可以直接关闭连接了;但是:_ 1. 我们知道网络是不稳定的,可能机器 B 发送了一些数据还没到达(比 FIN 包慢); 2. 同时回复的 ACK 包可能丢失了,机器 B 会重传 FIN 包; _如果此时机器 A 马上关闭连接,会导致数据不完整、机器 B 无法释放连接等问题。所以此时机器 A 需要等待 2 个报文生存最大时长,确保网络中没有任何遗留报文了,再关闭连接_ 5. 最后,机器 A 等待两个报文存活最大时长之后,机器 B 接收到 ACK 报文之后,均关闭连接,进入 CLASED 状态 双方之间 4 次互相发送报文来断开连接的过程,就是四次挥手。 现在,对于为什么握手是三次挥手是四次、一定要三次 / 四次吗、为什么要停留 2msl 再关闭连接等等这些问题,就都解决了。 / UDP 协议 / 运输层协议除了 TCP,还有大名鼎鼎的 UDP。如果说 TCP 凭借他完善稳定的功能独树一帜,那 UDP 就是精简主义乱拳打死老师傅。 UDP 只实现了运输层最少的功能:进程间通信。对于应用层传下来的数据,UDP 只是附加一个首部就直接交给网络层了。UDP 的头部非常简单,只有三部分: * 源端口、目标端口:端口号用来区分主机的不同进程 * 校验码:用于校验数据包在传输的过程中没有出现错误,例如某个 1 变成了 0 * 长度:报文的长度 所以 UDP 的功能也只有两个:校验数据报是否发生错误、区分不同的进程通信。 但,TCP 的功能虽然多,但同时也是要付出相对应的代价。例如面向连接的特性,在建立和断开连接的时候会有开销;拥塞控制的特性,会限制传输的上限等等。下面来罗列一下 UDP 的优缺点: #### **UDP 的缺点** * 无法保证消息完整、正确到达,UDP 是一个不可靠的传输协议; * 缺少拥塞控制容易互相竞争资源导致网络系统瘫痪 #### **UDP 的优点** * 效率更快;不需要建立连接以及拥塞控制 * 连接更多的客户;没有连接状态,不需要为每个客户创建缓存等 * 分组首部字节少,开销小;TCP 首部固定首部是 20 字节,而 UDP 只有 8 字节;更小的首部意味着更大比例的数据部分 * 在一些需要高效率允许可限度误差的场景下可以使用。如直播场景,并不需要保证每个数据包都完整到达,允许一定的丢包率,这个时候 TCP 的可靠特性反而成为了累赘;精简的 UDP 更高的效率是更加适合的选择 * 可以进行广播;UDP 并不是面向连接的,所以可以同时对多个进程进行发送报文 #### **UDP 适用场景** UDP 适用于对传输模型需要应用层高度自定义、允许出现丢包、需要高效率的场景、需要广播;例如 * 视屏直播 * DNS * RIP 路由选择协议 / 其他补充 / #### **分块传输** 我们可以发现,运输层在传输数据的时候,并不是把整个数据包加个首部直接发送过去,而是会拆分成多个报文分开发送;那他这样做原因是什么? 有读者可能会想到:数据链路层限制了数据长度只能有 1460。那数据链路层为什么要这么限制?他的本质原因就是:网络是不稳定的。如果报文太长,那么极有可能在传输一般的时候突然中断了,这个时候就要整个数据重传,效率就降低了。把数据拆分成多个数据报,那么当某个数据报丢失,只需要重传该数据报即可。 那是不是拆分得越细越好?报文中数据字段长度太低,会使得首部的占比太大,这样首部就会成为网络传输最大的负担了。例如 1000 字节,每个报文首部是 40 字节,如果拆分成 10 个报文,那么只需要传输 400 字节的首部;而如果拆分成 1000 个,那么需要传输 40000 字节的首部,效率就极大地降低了。 #### **路由转换** 先看下图: 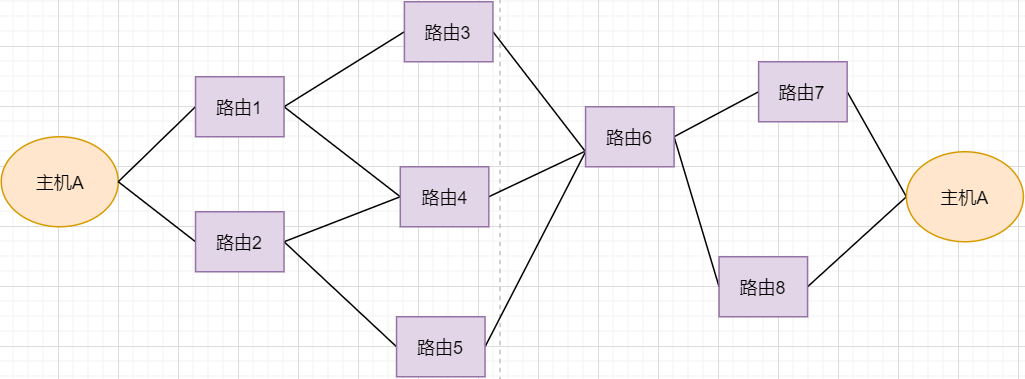 * 正常情况下,主机 A 的数据包可以又 1-3-6-7 路径进行传送 * 如果路由 3 坏掉了,那么可以从 1-4-6-7 进行传送 * 如果 4 也坏掉了,那么只能从 2-5-6-7 传送 * 如果 5 坏掉了,那么就中断线路了 可以看出来,使用路由转发的好处是:提高网络的容错率,本质原因依旧是网络是不稳定的 。即使坏掉几个路由器,网络依旧畅通。但是如果坏掉路由器 6 那就直接导致主机 A 和主机 B 无法通信,所以要避免这种核心路由器的存在。 使用路由的好处还有:分流。如果一条线路太拥堵,可以从别的路线进行传输,提高效率。 #### **粘包与拆包** 在面向字节流那一小节讲过,TCP 不懂这些数据流的意义,他只知道从应用层拿到数据流,切割成一份份报文,然后发送给目标对象。而如果应用层传输下来的是两个数据包,那么极有可能出现这种情况: 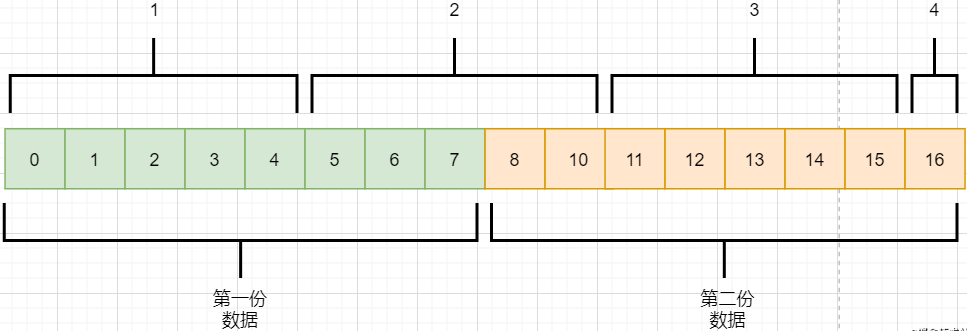 * 应用层需要向目标进程发送两份数据,一份音频,一份文本 * TCP 只知道接收到一个流,并把流拆分成 4 段进行发送 * 中间第二个报文的数据就出现两个文件的数据混在一起,这就是粘包 * 目标进程应用层在接收到数据之后,需要把这些数据拆分成正确的两个文件,就是拆包 粘包与拆包都是应用层需要解决的问题,可以在每个文件的最后附加上一些特殊的字节,如换行符;或者控制每个报文只包含一个文件的数据,不足的用 0 补充等等。 #### **恶意攻击** TCP 的面向连接特点可能会被恶意的人利用,对服务器进行攻击。 前面我们知道,当我们向一个主机发送 syn 包请求创建连接时,服务器会为我们创建缓冲区等,然后向我们返回 syn+ack 报文;如果我们伪造 IP 和端口,向一个服务器进行海量的请求,会使得服务器创建了大量的创建一半的 TCP 连接,使得其无法正常响应用户的请求,导致服务器瘫痪。 解决的方法可以有限制 IP 的创建连接数、让创建一半的 tcp 连接在更短的时间内自行关闭、延缓接收缓冲区内存的分配等等。 #### **长连接** 我们向服务器的每一次请求都需要创建一个 TCP 连接,服务器返回数据之后就会关闭连接;如果在短时间内有大量的请求,那么频繁创建 TCP 连接关闭 TCP 连接是一个很浪费资源的行为。所以我们可以让 TCP 连接不要关闭,在这个期间进行请求,提高效率。 需要注意长连接维持时间、创建条件等,避免被恶意利用创建大量的长连接,消耗殆尽服务器的资源。 / 最后 / 以前学习的时候觉得这些东西好像没什么卵用,貌似就是用来考试的。事实上,在没应用到的时候,对这些知识很难有更深层次的认知,例如现在我看上面的总结,很多只是表面上的认知,不知道他背后代表的真正含义。 但当我学习的更加广泛、深入,会对这些知识有越来越深刻的认识。有那么几个瞬间觉得:哦原来那个东西是这样运用,那个东西是这样的啊,原来学了是真的有用。 现在可能学了之后没有什么感觉,但是当用到或者学到相关的应用时,会有一个顿悟感,会瞬间收获很多。 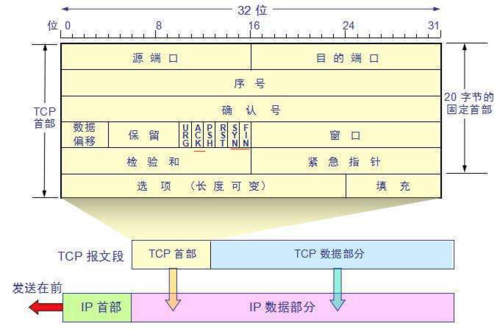 _链接:https://juejin.cn/user/3931509313252552/postse_ _(版权归原作者所有,侵删)_
Jonny
2022年6月23日 12:02
352
0 条评论
转发
收藏文檔
上一篇
下一篇
手机扫码
複製鏈接
手机扫一扫转发分享
複製鏈接
有些文档可能失效,请自行甄别!
【腾讯云】2核2G云服务器新老同享 99元/年,续费同价
【阿里云】2核2G云服务器新老同享 99元/年,续费同价(不要✓自动续费)
【腾讯云】2核2G云服务器新老同享 99元/年,续费同价
【阿里云】2核2G云服务器新老同享 99元/年,续费同价(不要✓自动续费)
分享
鏈接
類型
密碼
更新密碼
有效期
Markdown文件
Word文件
PDF文档
PDF文档(打印)
