技术文档收录
ASCII
Tcpdump
IPV4保留地址段
深入理解以太网网线原理 - 三帛的世界
白话 OSI 七层网络模型
Linux
WireGuard 一键安装脚本 | 秋水逸冰
SSH Config 那些你所知道和不知道的事 | Deepzz's Blog
Linux 让终端走代理的几种方法
ubuntu 20.04 server 版设置静态 IP 地址 - 链滴
Linux 挂载 Windows 共享磁盘的方法 - 技术学堂
将 SMB/CIFS 网络硬盘永久的挂载到 Ubuntu 上 - 简书
linux 获取当前脚本的绝对路径 | aimuke
[Linux] Linux 使用 / dev/urandom 生成随机数 - piaohua's blog
Linux 生成随机数的多种方法 | Just Do It
Linux 的 Centos7 版本下忘记 root 或者普通用户密码怎么办?
Git 强制拉取覆盖本地
SSH 安全加固指南 - FreeBuf 网络安全行业门户
Linux 系统安全强化指南 - FreeBuf 网络安全行业门户
Linux 入侵排查 - FreeBuf 网络安全行业门户
sshd_config 配置详解 - 简书
SSH 权限详解 - SegmentFault 思否
CentOS 安装 node.js 环境 - SegmentFault 思否
如何在 CentOS 7 上安装 Node.js 和 npm | myfreax
几款 ping tcping 工具总结
OpenVpn 搭建教程 | Jesse's home
openvpn 一键安装脚本 - 那片云
OpenVPN 解决 每小时断线一次 - 爱开源
OpenVPN 路由设置 – 凤曦的小窝
OpenVPN 设置非全局代理 - 镜子的记录簿
TinyProxy 使用帮助 - 简书
Ubuntu 下使用 TinyProxy 搭建代理 HTTP 服务器_Linux_运维开发网_运维开发技术经验分享
Linux 软件包管理工具 Snap 常用命令 - 简书
linux systemd 参数详解
Systemd 入门教程:命令篇 - 阮一峰的网络日志
记一次 Linux 木马清除过程
rtty:在任何地方通过 Web 访问您的终端
02 . Ansible 高级用法 (运维开发篇)
终于搞懂了服务器为啥产生大量的 TIME_WAIT!
巧妙的 Linux 命令,再来 6 个!
77% 的 Linux 运维都不懂的内核问题,这篇全告诉你了
运维工程师必备:请收好 Linux 网络命令集锦
一份阿里员工的 Java 问题排查工具单
肝了 15000 字性能调优系列专题(JVM、MySQL、Nginx and Tomcat),看不完先收
作业调度算法(FCFS,SJF,优先级调度,时间片轮转,多级反馈队列) | The Blog Of WaiterXiaoYY
看了这篇还不会 Linux 性能分析和优化,你来打我
2019 运维技能风向标
更安全的 rm 命令,保护重要数据
求你了,别再纠结线程池大小了!
Linux sudo 详解 | 失落的乐章
重启大法好!线上常见问题排查手册
sudo 使用 - 笨鸟教程的博客 | BY BenderFly
shell 在手分析服务器日志不愁? - SegmentFault 思否
sudo 与 visudo 的超细用法说明_陈发哥 007 的技术博客_51CTO 博客
ESXI 下无损扩展 Linux 硬盘空间 | Naonao Blog
Linux 学习记录:su 和 sudo | Juntao Tan 的个人博客
使用者身份切换 | Linux 系统教程(笔记)
你会使用 Linux 编辑器 vim 吗?
在 Windows、Linux 和 Mac 上查看 Wi-Fi 密码
linux 隐藏你的 crontab 后门 - 简书
Linux 定时任务详解 - Tr0y's Blog
linux 的 TCP 连接数量最大不能超过 65535 个吗,那服务器是如何应对百万千万的并发的?_一口 Linux 的博客 - CSDN 博客_tcp 连接数多少正常
万字长文 + 28 张图,一次性说清楚 TCP,运维必藏
为什么 p2p 模式的 tunnel 底层通常用 udp 而不是 tcp?
记一次服务器被入侵挖矿 - tlanyan
shell 判断一个变量是否为空方法总结 - 腾讯云开发者社区 - 腾讯云
系统安装包管理工具 | Escape
编译代码时动态地链接库 - 51CTO.COM
甲骨文 Oracle Cloud 添加新端口开放的方法 - WirelessLink 社区
腾讯云 Ubuntu 添加 swap 分区的方法_弓弧名家_玄真君的博客 - CSDN 博客
Oracle 开放全部端口并关闭防火墙 - 清~ 幽殇
谁再说不熟悉 Linux 命令, 就把这个给他扔过去!
即插即用,运维工程师必会正则表达式大全
Shell脚本编写及常见面试题
Samba 文件共享服务器
到底一台服务器上最多能创建多少个 TCP 连接 | plantegg
SSH 密钥登录 - SSH 教程 - 网道
在 Bash 中进行 encodeURIComponent/decodeURIComponent | Harttle Land
使用 Shell 脚本来处理 JSON - Tom CzHen's Blog
Docker
「Docker」 - 保存镜像 - 知乎
终于可以像使用 Docker 一样丝滑地使用 Containerd 了!
私有镜像仓库选型:Harbor VS Quay - 乐金明的博客 | Robin Blog
exec 与 entrypoint 使用脚本 | Mr.Cheng
Dockerfile 中的 CMD 与 ENTRYPOINT
使用 Docker 配置 MySQL 主从数据库 - 墨天轮
Alpine vs Distroless vs Busybox – 云原生实验室 - Kubernetes|Docker|Istio|Envoy|Hugo|Golang | 云原生
再见,Docker!
docker save 与 docker export 的区别 - jingsam
如何优雅的关闭容器
docker 储存之 tmpfs 、bind-mounts、volume | 陌小路的个人博客
Dockerfile 中 VOLUME 与 docker -v 的区别是什么 - 开发技术 - 亿速云
理解 docker 容器的退出码 | Vermouth | 博客 | docker | k8s | python | go | 开发
【Docker 那些事儿】容器监控系统,来自 Docker 的暴击_飞向星的客机的博客 - CSDN 博客
【云原生】Docker 镜像详细讲解_微枫 Micromaple 的博客 - CSDN 博客_registry-mirrors
【云原生】Helm 架构和基础语法详解
CMD 和 Entrypoint 命令使用变量的用法
实时查看容器日志 - 苏洋博客
Traefik 2 使用指南,愉悦的开发体验 - 苏洋博客
为你的 Python 应用选择一个最好的 Docker 映像 | 亚马逊 AWS 官方博客
【云原生】镜像构建实战操作(Dockerfile)
Docker Compose 中的 links 和 depends_on 的区别 - 编程知识 - 白鹭情
Python
Pipenv:新一代Python项目环境与依赖管理工具 - 知乎
Python list 列表实现栈和队列
Python 各种排序 | Lesley's blog
Python 中使用 dateutil 模块解析时间 - SegmentFault 思否
一个小破网站,居然比 Python 官网还牛逼
Python 打包 exe 的王炸 - Nuitka
Django - - 基础 - - Django ORM 常用查询语法及进阶
[Python] 小知識:== 和 is 的差異 - Clay-Technology World
Window
批处理中分割字符串 | 网络进行时
Windows 批处理基础命令学习 - 简书
在Windows上设置WireGuard
Windows LTSC、LTSB、Server 安装 Windows Store 应用商店
windows 重启 rdpclip.exe 的脚本
中间件
Nginx 中的 Rewrite 的重定向配置与实践
RabbitMQ 的监控
RabbitMq 最全的性能调优笔记 - SegmentFault 思否
为什么不建议生产用 Redis 主从模式?
高性能消息中间件——NATS
详解:Nginx 反代实现 Kibana 登录认证功能
分布式系统关注点:仅需这一篇,吃透 “负载均衡” 妥妥的
仅需这一篇,妥妥的吃透” 负载均衡”
基于 nginx 实现上游服务器动态自动上下线——不需 reload
Nginx 学习书单整理
最常见的日志收集架构(ELK Stack)
分布式之 elk 日志架构的演进
CAT 3.0 开源发布,支持多语言客户端及多项性能提升
Kafka 如何做到 1 秒处理 1500 万条消息?
Grafana 与 Kibana
ELK 日志系统之通用应用程序日志接入方案
ELK 简易 Nginx 日志系统搭建: ElasticSearch+Kibana+Filebeat
记一次 Redis 连接池问题引发的 RST
把 Redis 当作队列来用,你好大的胆子……
Redis 最佳实践:业务层面和运维层面优化
Redis 为什么变慢了?常见延迟问题定位与分析
好饭不怕晚,扒一下 Redis 配置文件的底 Ku
rabbitmq 集群搭建以及万级并发下的性能调优
别再问我 Redis 内存满了该怎么办了
Nginx 状态监控及日志分析
uWSGI 的安装及配置详解
uwsgi 异常服务器内存 cpu 爆满优化思路
Uwsgi 内存占用过多 - 简书
Nginx 的 limit 模块
Nginx 内置模块简介
Redis 忽然变慢了如何排查并解决?_redis_码哥字节_InfoQ 写作社区
领导:谁再用 redis 过期监听实现关闭订单,立马滚蛋!
Nginx 限制 IP 访问频率以及白名单配置_问轩博客
Nginx $remote_addr 和 $proxy_add_x_forwarded_for 变量详解
Caddy 部署实践
一文搞定 Nginx 限流
数据库
SqlServer 将数据库中的表复制到另一个数据库_MsSql_脚本之家
SQL Server 数据库同步,订阅、发布、复制、跨服务器
sql server 无法删除本地发布 | 辉克's Blog
SQLite全文检索
SQL 重复记录查询的几种方法 - 简书
SQL SERVER 使用订阅发布同步数据库(转)
Mysql 查看用户连接数配置及每个 IP 的请求情况 - 墨天轮
优化 SQL 的 21 条方案
SQL Server 连接时好时坏的奇怪问题
MS SQL 执行大脚本文件时,提示 “内存不足” 的解决办法 - 阿里云开发者社区
防火墙-iptables
iptables 常用规则:屏蔽 IP 地址、禁用 ping、协议设置、NAT 与转发、负载平衡、自定义链
防火墙 iptables 企业防火墙之 iptables
Linux 防火墙 ufw 简介
在 Ubuntu 中用 UFW 配置防火墙
在 Ubuntu20.04 上怎样使用 UFW 配置防火墙 - 技术库存网
监控类
开箱即用的 Prometheus 告警规则集
prometheus☞搭建 | zyh
docker 部署 Prometheus 监控服务器及容器并发送告警 | chris'wang
PromQL 常用命令 | LRF 成长记
prometheus 中使用 python 手写 webhook 完成告警
持续集成CI/CD
GitHub Actions 的应用场景 | 记录干杯
GithubActions · Mr.li's Blog
工具类
GitHub 中的开源网络广告杀手,十分钟快速提升网络性能
SSH-Auditor:一款 SHH 弱密码探测工具
别再找了,Github 热门开源富文本编辑器,最实用的都在这里了 - srcmini
我最喜欢的 CLI 工具
推荐几款 Redis 可视化工具
内网代理工具与检测方法研究
环境篇:数据同步工具 DataX
全能系统监控工具 dstat
常用 Web 安全扫描工具合集
给你一款利器!轻松生成 Nginx 配置文件
教程类
Centos7 搭建神器 openvpn | 运维随笔
搭建 umami 收集个人网站统计数据 | Reorx’s Forge
openvpn安装教程
基于 gitea+drone 完成小团队的 CI/CD - 德国粗茶淡饭
将颜色应用于交替行或列
VMware Workstation 全系列合集 精简安装注册版 支持 SLIC2.6、MSDM、OSX 更新 16.2.3_虚拟机讨论区_安全区 卡饭论坛 - 互助分享 - 大气谦和!
在 OpenVPN 上启用 AD+Google Authenticator 认证 | 运维烂笔头
Github 进行 fork 后如何与原仓库同步:重新 fork 很省事,但不如反复练习版本合并 · Issue #67 · selfteaching/the-craft-of-selfteaching
卧槽,VPN 又断开了!!- 阿里云开发者社区
Grafana Loki 学习之踩坑记
zerotier 的 planet 服务器(根服务器)的搭建踩坑记。无需 zerotier 官网账号。
阿里云 qcow2 镜像转 vmdk,导入 ESXi - 唐际忠的博客
Caddy 入门 – 又见杜梨树
【Caddy2】最新 Caddy2 配置文件解析 - Billyme 的博客
Web 服务器 Caddy 2 | Haven200
手把手教你打造高效的 Kubernetes 命令行终端
Keras 作者:给软件开发者的 33 条黄金法则
超详细的网络抓包神器 Tcpdump 使用指南
使用 fail2ban 和 FirewallD 黑名单保护你的系统
linux 下 mysql 数据库单向同步配置方法分享 (Mysql)
MySQL 快速删除大量数据(千万级别)的几种实践方案
GitHub 上的优质 Linux 开源项目,真滴牛逼!
WireGuard 教程:使用 Netmaker 来管理 WireGuard 的配置 – 云原生实验室 - Kubernetes|Docker|Istio|Envoy|Hugo|Golang | 云原生
Tailscale 基础教程:Headscale 的部署方法和使用教程 – 云原生实验室 - Kubernetes|Docker|Istio|Envoy|Hugo|Golang | 云原生
Nebula Graph 的 Ansible 实践
改进你的 Ansible 剧本的 4 行代码
Caddy 2 快速简单安装配置教程 – 高玩梁的博客
切换至 Caddy2 | 某不科学的博客
Caddy2 简明教程 - bleem
树莓派安装 OpenWrt 突破校园网限制 | Asttear's Blog
OpenVPN 路由设置 – 凤曦的小窝
个性化编译 LEDE 固件
盘点各种 Windows/Office 激活工具
[VirtualBox] 1、NAT 模式下端口映射
VirtualBox 虚拟机安装 openwrt 供本机使用
NUC 折腾笔记 - 安装 ESXi 7 - 苏洋博客
锐捷、赛尔认证 MentoHUST - Ubuntu 中文
How Do I Use A Client Certificate And Private Key From The IOS Keychain? | OpenVPN
比特记事簿: 笔记: 使用电信 TR069 内网架设 WireGuard 隧道异地组网
利用 GitHub API 获取最新 Releases 的版本号 | 这是只兔子
docsify - 生成文档网站简单使用教程 - SegmentFault 思否
【干货】Chrome 插件 (扩展) 开发全攻略 - 好记的博客
一看就会的 GitHub 骚操作,让你看上去像一位开源大佬
【计算机网络】了解内网、外网、宽带、带宽、流量、网速_墩墩分墩 - CSDN 博客
mac-ssh 配置 | Sail
如何科学管理你的密码
VirtualBox NAT 端口映射实现宿主机与虚拟机相互通信 | Shao Guoliang 的博客
CentOS7 配置网卡为静态 IP,如果你还学不会那真的没有办法了!
laisky-blog: 近期折腾 tailscale 的一些心得
使用 acme.sh 给 Nginx 安装 Let’ s Encrypt 提供的免费 SSL 证书 · Ruby China
acme 申请 Let’s Encrypt 泛域名 SSL 证书
从 nginx 迁移到 caddy
使用 Caddy 替代 Nginx,全站升级 https,配置更加简单 - Diamond-Blog
http.proxy - Caddy 中文文档
动手撸个 Caddy(二)| Caddy 命令行参数最全教程 | 飞雪无情的总结
Caddy | 学习笔记 - ijayer
Caddy 代理 SpringBoot Fatjar 应用上传静态资源
使用 graylog3.0 收集 open××× 日志进行审计_年轻人,少吐槽,多搬砖的技术博客_51CTO 博客
提高国内访问 github 速度的 9 种方法! - SegmentFault 思否
VM16 安装 macOS 全网最详细
2022 目前三种有效加速国内 Github
How to install MariaDB on Alpine Linux | LibreByte
局域网内电脑 - ipad 文件共享的三种方法 | 岚
多机共享键鼠软件横向测评 - 尚弟的小笔记
VLOG | ESXI 如何升级到最新版,无论是 6.5 还是 6.7 版本都可以顺滑升级。 – Vedio Talk - VLOG、科技、生活、乐分享
远程修改 ESXi 6.7 管理 IP 地址 - 腾讯云开发者社区 - 腾讯云
几乎不要钱自制远程 PLC 路由器方案
traefik 简易入门 | 个人服务器运维指南 | 山月行
更完善的 Docker + Traefik 使用方案 - 苏洋博客
MicroSD·TF 卡终极探秘 ·MLC 颗粒之谜 1 三星篇_microSD 存储卡_什么值得买
macOS 绕过公证和应用签名方法 - 走客
MiscSecNotes / 内网端口转发及穿透. md at master · JnuSimba/MiscSecNotes
我有特别的 DNS 配置和使用技巧 | Sukka's Blog
SEO:初学者完整指南
通过 OpenVPN 实现流量审计
OpenVPN-HOWTO
OpenVPN Server · Devops Roadmap
Linux 运维必备的 13 款实用工具, 拿好了~
linux 平台下 Tomcat 的安装与优化
Linux 运维跳槽必备的 40 道面试精华题
Bash 脚本进阶,经典用法及其案例 - alonghub - 博客园
推荐几个非常不错的富文本编辑器 - 走看看
在 JS 文件中加载 JS 文件的方法 - 月光博客
#JavaScript 根据需要动态加载脚本并设置自定义参数
笔记本电脑 BIOS 修改及刷写教程
跨平台加密 DNS 和广告过滤 personalDNSfilter · LinuxTOY
AdGuard Home 安装及使用指北
通过 Amazon S3 协议挂载 OSS
记一次云主机如何挂载对象存储
(续)acme.sh 脚本使用新 cloudflare api 令牌申请证书 - 世界你好
本文档发布于https://mrdoc.fun
-
+
首頁
Django - - 基础 - - Django ORM 常用查询语法及进阶
> 本文由 [简悦 SimpRead](http://ksria.com/simpread/) 转码, 原文地址 [www.cnblogs.com](https://www.cnblogs.com/xiaoqshuo/p/10025773.html) 目录 == * 一般操作 * 必知必会 13 条 * 单表查询之神奇的双下划线 * ForeignKey 操作 * 正向查找 * 反向操作 * ManyToManyField * class RelatedManager * 聚合查询和分组查询 * 聚合 * 分组 * F 查询和 Q 查询 * F 查询 * Q 查询 * 锁和事务 * 锁 * 事务 * 其他鲜为人知的操作(有个印象即可) * Django ORM 执行原生 SQL * QuerySet 方法大全 * Django 终端打印 SQL 语句 * 在 Python 脚本中调用 Django 环境 1, 一般操作 ------- * 官网文档:[https://docs.djangoproject.com/en/1.11/ref/models/querysets/](https://docs.djangoproject.com/en/1.11/ref/models/querysets/) ### 1.1 必知必会 13 条 ``` <1> all(): 查询所有结果 <2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 <3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。 <4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 <5> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列 <6> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 <7> order_by(*field): 对查询结果排序 <8> reverse(): 对查询结果反向排序,请注意reverse()通常只能在具有已定义顺序的QuerySet上调用(在model类的Meta中指定ordering或调用order_by()方法)。 <9> distinct(): 从返回结果中剔除重复纪录(如果你查询跨越多个表,可能在计算QuerySet时得到重复的结果。此时可以使用distinct(),注意只有在PostgreSQL中支持按字段去重。) <10> count(): 返回数据库中匹配查询(QuerySet)的对象数量。 <11> first(): 返回第一条记录 <12> last(): 返回最后一条记录 <13> exists(): 如果QuerySet包含数据,就返回True,否则返回False ``` #### 1.1.1 返回 QuerySet 对象的方法有 * all() * filter() * exclude() * order_by() * reverse() * distinct() #### 1.1.2 特殊的 QuerySet * values() 返回一个可迭代的字典序列 * values_list() 返回一个可迭代的元祖序列 #### 1.1.3 返回具体对象的 * get() * first() * last() #### 1.1.4 返回布尔值的方法有: * exists() #### 1.1.5 返回数字的方法有 * count() ### 1.2 单表查询之神奇的双下划线 ``` models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值 models.Tb1.objects.filter(id__gte=1) # greater than equal 获取id大于等于1 的值 models.Tb1.objects.filter(id__lte=10) # less than equal 获取id小于等于10 的值 models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据 models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in models.Tb1.objects.filter(name__contains="ven") # 获取name字段包含"ven"的 models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感 models.Tb1.objects.filter(id__range=[1, 3]) # id范围是1到3的,等价于SQL的bettwen and 类似的还有:startswith,istartswith, endswith, iendswith date字段还可以: models.Class.objects.filter(first_day__year=2017) ``` 2, ForeignKey 操作 ---------------- ### 2.1 正向查找 #### 2.1.1 对象查找(跨表) * 语法: * 对象. 关联字段. 字段 * 示例: ``` book_obj = models.Book.objects.first() # 第一本书对象 print(book_obj.publisher) # 得到这本书关联的出版社对象 print(book_obj.publisher.name) # 得到出版社对象的名称 ``` #### 2.1.2 字段查找(跨表) * 语法: * 关联字段__字段 * 示例: ``` print(models.Book.objects.values_list("publisher__name")) ``` ### 2.2 反向操作 #### 2.2.1 对象查找 * 语法: * `obj.表名_set` * 示例: ``` publisher_obj = models.Publisher.objects.first() # 找到第一个出版社对象 books = publisher_obj.book_set.all() # 找到第一个出版社出版的所有书 titles = books.values_list("title") # 找到第一个出版社出版的所有书的书名 ``` #### 2.2.2 字段查找 * 语法: * 表名__字段 * 示例: ``` titles = models.Publisher.objects.values_list("book__title") ``` 3, ManyToManyField ------------------ ### 3.1 class RelatedManager * "关联管理器" 是在一对多或者多对多的关联上下文中使用的管理器。 * 它存在于下面两种情况: * 外键关系的反向查询 * 多对多关联关系 * 简单来说就是当 点后面的对象 可能存在多个的时候就可以使用以下的方法。 #### 3.1.1 方法 * create() * 创建一个新的对象,保存对象,并将它添加到关联对象集之中,返回新创建的对象。 ``` >>> import datetime >>> models.Author.objects.first().book_set.create(title="番茄物语", publish_date=datetime.date.today()) ``` * add() * 把指定的 model 对象添加到关联对象集中。 * 添加对象 ``` >>> author_objs = models.Author.objects.filter(id__lt=3) >>> models.Book.objects.first().authors.add(*author_objs) ``` * 添加 id ``` >>> models.Book.objects.first().authors.add(*[1, 2]) ``` * set() * 更新 model 对象的关联对象。 ``` >>> book_obj = models.Book.objects.first() >>> book_obj.authors.set([2, 3]) ``` * remove() * 从关联对象集中移除执行的 model 对象 ``` >>> book_obj = models.Book.objects.first() >>> book_obj.authors.remove(3) ``` * clear() * 从关联对象集中移除一切对象。 ``` >>> book_obj = models.Book.objects.first() >>> book_obj.authors.clear() ``` * 注意: * 对于 ForeignKey 对象,clear() 和 remove() 方法仅在 null=True 时存在。 * 举个例子: * ForeignKey 字段没设置 null=True 时, ``` class Book(models.Model): title = models.CharField(max_length=32) publisher = models.ForeignKey(to=Publisher) ``` * 没有 clear() 和 remove() 方法: ``` >>> models.Publisher.objects.first().book_set.clear() Traceback (most recent call last): File "<input>", line 1, in <module> AttributeError: 'RelatedManager' object has no attribute 'clear' ``` * 当 ForeignKey 字段设置 null=True 时, ``` class Book(models.Model): name = models.CharField(max_length=32) publisher = models.ForeignKey(to=Class, null=True) ``` * 此时就有 clear() 和 remove() 方法: ``` >>> models.Publisher.objects.first().book_set.clear() ``` * 注意: * 对于所有类型的关联字段,add()、create()、remove() 和 clear(),set() 都会马上更新数据库。换句话说,在关联的任何一端,都不需要再调用 save() 方法。 4, 聚合查询和分组查询 ------------ ### 4.1 聚合 * aggregate() 是 QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。 * 键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。 * 用到的内置函数: ``` from django.db.models import Avg, Sum, Max, Min, Count ``` * 示例: ``` >>> from django.db.models import Avg, Sum, Max, Min, Count >>> models.Book.objects.all().aggregate(Avg("price")) {'price__avg': 13.233333} ``` * 如果你想要为聚合值指定一个名称,可以向聚合子句提供它。 ``` >>> models.Book.objects.aggregate(average_price=Avg('price')) {'average_price': 13.233333} ``` * 如果你希望生成不止一个聚合,你可以向 aggregate() 子句中添加另一个参数。所以,如果你也想知道所有图书价格的最大值和最小值,可以这样查询: ``` >>> models.Book.objects.all().aggregate(Avg("price"), Max("price"), Min("price")) {'price__avg': 13.233333, 'price__max': Decimal('19.90'), 'price__min': Decimal('9.90')} ``` ### 4.2 分组 * 我们在这里先复习一下 SQL 语句的分组。 * 假设现在有一张公司职员表: 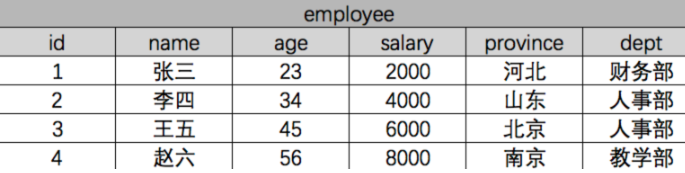 * 使用原生 SQL 语句,按照部分分组求平均工资: ``` select dept,AVG(salary) from employee group by dept; ``` * ORM 查询: ``` from django.db.models import Avg Employee.objects.values("dept").annotate(avg=Avg("salary").values(dept, "avg") ``` * 连表查询的分组:  * SQL 查询: ``` select dept.name,AVG(salary) from employee inner join dept on (employee.dept_id=dept.id) group by dept_id; ``` * ORM 查询: ``` from django.db.models import Avg models.Dept.objects.annotate(avg=Avg("employee__salary")).values("name", "avg") ``` ### 4.3 更多示例: * 示例 1:统计每一本书的作者个数 ``` >>> book_list = models.Book.objects.all().annotate(author_num=Count("author")) >>> for obj in book_list: ... print(obj.author_num) ... 2 1 1 ``` * 示例 2:统计出每个出版社买的最便宜的书的价格 ``` >>> publisher_list = models.Publisher.objects.annotate(min_price=Min("book__price")) >>> for obj in publisher_list: ... print(obj.min_price) ... 9.90 19.90 方法二: >>> models.Book.objects.values("publisher__name").annotate(min_price=Min("price")) <QuerySet [{'publisher__name': '沙河出版社', 'min_price': Decimal('9.90')}, {'publisher__name': '人民出版社', 'min_price': Decimal('19.90')}]> ``` * 示例 3:统计不止一个作者的图书 ``` >>> models.Book.objects.annotate(author_num=Count("author")).filter(author_num__gt=1) <QuerySet [<Book: 番茄物语>]> ``` * 示例 4:根据一本图书作者数量的多少对查询集 QuerySet 进行排序 ``` >>> models.Book.objects.annotate(author_num=Count("author")).order_by("author_num") <QuerySet [<Book: 香蕉物语>, <Book: 橘子物语>, <Book: 番茄物语>]> ``` * 示例 5:查询各个作者出的书的总价格 ``` >>> models.Author.objects.annotate(sum_price=Sum("book__price")).values("name", "sum_price") <QuerySet [{'name': '小精灵', 'sum_price': Decimal('9.90')}, {'name': '小仙女', 'sum_price': Decimal('29.80')}, {'name': '小魔女', 'sum_price': Decimal('9.90')}]> ``` 5 F 查询和 Q 查询 ------------ ### 5.1 F 查询 * 在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢? * Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。 * 示例 1: * 查询评论数大于收藏数的书籍 ``` from django.db.models import F models.Book.objects.filter(commnet_num__gt=F('keep_num')) ``` * Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。 ``` models.Book.objects.filter(commnet_num__lt=F('keep_num')*2) ``` * 修改操作也可以使用 F 函数, 比如将每一本书的价格提高 30 元 ``` models.Book.objects.all().update(price=F("price")+30) ``` * 引申: * 如果要修改 char 字段咋办? * 如:把所有书名后面加上 (第一版) ``` >>> from django.db.models.functions import Concat >>> from django.db.models import Value >>> models.Book.objects.all().update(title=Concat(F("title"), Value("("), Value("第一版"), Value(")"))) ``` ### 5.2 Q 查询 * filter() 等方法中的关键字参数查询都是一起进行 “AND” 的。 如果你需要执行更复杂的查询(例如 OR 语句),你可以使用 Q 对象。 * 示例 1: * 查询作者名是小仙女或小魔女的 ``` models.Book.objects.filter(Q(authors__name="小仙女")|Q(authors__name="小魔女")) ``` * 你可以组合 & 和 | 操作符以及使用括号进行分组来编写任意复杂的 Q 对象。同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反 (NOT) 查询。 * 示例:查询作者名字是小仙女并且不是 2018 年出版的书的书名。 ``` >>> models.Book.objects.filter(Q(author__name="小仙女") & ~Q(publish_date__year=2018)).values_list("title") <QuerySet [('番茄物语',)]> ``` * 查询函数可以混合使用 Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或 Q 对象)都将 "AND” 在一起。但是,如果出现 Q 对象,它必须位于所有关键字参数的前面。 * 例如:查询出版年份是 2017 或 2018,书名中带物语的所有书。 ``` >>> models.Book.objects.filter(Q(publish_date__year=2018) | Q(publish_date__year=2017), title__icontains="物语") <QuerySet [<Book: 番茄物语>, <Book: 香蕉物语>, <Book: 橘子物语>]> ``` 6 锁和事务 ------ ### 6.1 锁 ``` select_for_update(nowait=False, skip_locked=False) ``` * 返回一个锁住行直到事务结束的查询集,如果数据库支持,它将生成一个 SELECT ... FOR UPDATE 语句。 * 举个例子: ``` entries = Entry.objects.select_for_update().filter(author=request.user) ``` * 所有匹配的行将被锁定,直到事务结束。这意味着可以通过锁防止数据被其它事务修改。 * 一般情况下如果其他事务锁定了相关行,那么本查询将被阻塞,直到锁被释放。 如果这不想要使查询阻塞的话,使用`select_for_update(nowait=True)`。 如果其它事务持有冲突的锁, 那么查询将引发 DatabaseError 异常。你也可以使用`select_for_update(skip_locked=True)`忽略锁定的行。 nowait 和 skip_locked 是互斥的,同时设置会导致 ValueError。 * 目前,postgresql,oracle 和 mysql 数据库后端支持 select_for_update()。 但是,MySQL 不支持 nowait 和 skip_locked 参数。 * 使用不支持这些选项的数据库后端(如 MySQL)将 nowait=True 或 skip_locked=True 转换为 select_for_update() 将导致抛出 DatabaseError 异常,这可以防止代码意外终止。 ### 6.2 事务 ``` import os if __name__ == '__main__': os.environ.setdefault("DJANGO_SETTINGS_MODULE", "BMS.settings") import django django.setup() import datetime from app01 import models try: from django.db import transaction with transaction.atomic(): new_publisher = models.Publisher.objects.create(name="火星出版社") models.Book.objects.create(title="橘子物语", publish_date=datetime.date.today(), publisher_id=10) # 指定一个不存在的出版社id except Exception as e: print(str(e)) ``` 7 其他鲜为人知的操作(有个印象即可) ------------------- ### 7.1 Django ORM 执行原生 SQL * 在模型查询 API 不够用的情况下,我们还可以使用原始的 SQL 语句进行查询。 * Django 提供两种方法使用原始 SQL 进行查询:一种是使用 raw() 方法,进行原始 SQL 查询并返回模型实例;另一种是完全避开模型层,直接执行自定义的 SQL 语句。 #### 7.1.1 执行原生查询 * raw() 管理器方法用于原始的 SQL 查询,并返回模型的实例: * 注意:raw() 语法查询必须包含主键。 * 这个方法执行原始的 SQL 查询,并返回一个 django.db.models.query.RawQuerySet 实例。 这个 RawQuerySet 实例可以像一般的 QuerySet 那样,通过迭代来提供对象实例。 * 举个例子: ``` class Person(models.Model): first_name = models.CharField(...) last_name = models.CharField(...) birth_date = models.DateField(...) ``` * 可以像下面这样执行原生 SQL 语句 ``` >>> for p in Person.objects.raw('SELECT * FROM myapp_person'): ... print(p) ``` * raw() 查询可以查询其他表的数据。 * 举个例子: ``` ret = models.Student.objects.raw('select id, tname as hehe from app02_teacher') for i in ret: print(i.id, i.hehe) ``` * raw() 方法自动将查询字段映射到模型字段。还可以通过 translations 参数指定一个把查询的字段名和 ORM 对象实例的字段名互相对应的字典 ``` d = {'tname': 'haha'} ret = models.Student.objects.raw('select * from app02_teacher', translations=d) for i in ret: print(i.id, i.sname, i.haha) ``` * 原生 SQL 还可以使用参数,注意不要自己使用字符串格式化拼接 SQL 语句,防止 SQL 注入! ``` d = {'tname': 'haha'} ret = models.Student.objects.raw('select * from app02_teacher where id > %s', translations=d, params=[1,]) for i in ret: print(i.id, i.sname, i.haha) ``` #### 7.1.2 直接执行自定义 SQL * 有时候 raw() 方法并不十分好用,很多情况下我们不需要将查询结果映射成模型,或者我们需要执行 DELETE、 INSERT 以及 UPDATE 操作。在这些情况下,我们可以直接访问数据库,完全避开模型层。 * 我们可以直接从 django 提供的接口中获取数据库连接,然后像使用 pymysql 模块一样操作数据库。 ``` from django.db import connection, connections cursor = connection.cursor() # cursor = connections['default'].cursor() cursor.execute("""SELECT * from auth_user where id = %s""", [1]) ret = cursor.fetchone() ``` ### 7.2 QuerySet 方法大全 ``` ################################################################## # PUBLIC METHODS THAT ALTER ATTRIBUTES AND RETURN A NEW QUERYSET # ################################################################## def all(self) # 获取所有的数据对象 def filter(self, *args, **kwargs) # 条件查询 # 条件可以是:参数,字典,Q def exclude(self, *args, **kwargs) # 条件查询 # 条件可以是:参数,字典,Q def select_related(self, *fields) 性能相关:表之间进行join连表操作,一次性获取关联的数据。 总结: 1. select_related主要针一对一和多对一关系进行优化。 2. select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。 def prefetch_related(self, *lookups) 性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。 总结: 1. 对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。 2. prefetch_related()的优化方式是分别查询每个表,然后用Python处理他们之间的关系。 def annotate(self, *args, **kwargs) # 用于实现聚合group by查询 from django.db.models import Count, Avg, Max, Min, Sum v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')) # SELECT u_id, COUNT(ui) AS `uid` FROM UserInfo GROUP BY u_id v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')).filter(uid__gt=1) # SELECT u_id, COUNT(ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1 v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id',distinct=True)).filter(uid__gt=1) # SELECT u_id, COUNT( DISTINCT ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1 def distinct(self, *field_names) # 用于distinct去重 models.UserInfo.objects.values('nid').distinct() # select distinct nid from userinfo 注:只有在PostgreSQL中才能使用distinct进行去重 def order_by(self, *field_names) # 用于排序 models.UserInfo.objects.all().order_by('-id','age') def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None) # 构造额外的查询条件或者映射,如:子查询 Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,)) Entry.objects.extra(where=['headline=%s'], params=['Lennon']) Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"]) Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid']) def reverse(self): # 倒序 models.UserInfo.objects.all().order_by('-nid').reverse() # 注:如果存在order_by,reverse则是倒序,如果多个排序则一一倒序 def defer(self, *fields): models.UserInfo.objects.defer('username','id') 或 models.UserInfo.objects.filter(...).defer('username','id') #映射中排除某列数据 def only(self, *fields): #仅取某个表中的数据 models.UserInfo.objects.only('username','id') 或 models.UserInfo.objects.filter(...).only('username','id') def using(self, alias): 指定使用的数据库,参数为别名(setting中的设置) ################################################## # PUBLIC METHODS THAT RETURN A QUERYSET SUBCLASS # ################################################## def raw(self, raw_query, params=None, translations=None, using=None): # 执行原生SQL models.UserInfo.objects.raw('select * from userinfo') # 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名 models.UserInfo.objects.raw('select id as nid from 其他表') # 为原生SQL设置参数 models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,]) # 将获取的到列名转换为指定列名 name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'} Person.objects.raw('SELECT * FROM some_other_table', translations=name_map) # 指定数据库 models.UserInfo.objects.raw('select * from userinfo', using="default") ################### 原生SQL ################### from django.db import connection, connections cursor = connection.cursor() # cursor = connections['default'].cursor() cursor.execute("""SELECT * from auth_user where id = %s""", [1]) row = cursor.fetchone() # fetchall()/fetchmany(..) def values(self, *fields): # 获取每行数据为字典格式 def values_list(self, *fields, **kwargs): # 获取每行数据为元祖 def dates(self, field_name, kind, order='ASC'): # 根据时间进行某一部分进行去重查找并截取指定内容 # kind只能是:"year"(年), "month"(年-月), "day"(年-月-日) # order只能是:"ASC" "DESC" # 并获取转换后的时间 - year : 年-01-01 - month: 年-月-01 - day : 年-月-日 models.DatePlus.objects.dates('ctime','day','DESC') def datetimes(self, field_name, kind, order='ASC', tzinfo=None): # 根据时间进行某一部分进行去重查找并截取指定内容,将时间转换为指定时区时间 # kind只能是 "year", "month", "day", "hour", "minute", "second" # order只能是:"ASC" "DESC" # tzinfo时区对象 models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.UTC) models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.timezone('Asia/Shanghai')) """ pip3 install pytz import pytz pytz.all_timezones pytz.timezone(‘Asia/Shanghai’) """ def none(self): # 空QuerySet对象 #################################### # METHODS THAT DO DATABASE QUERIES # #################################### def aggregate(self, *args, **kwargs): # 聚合函数,获取字典类型聚合结果 from django.db.models import Count, Avg, Max, Min, Sum result = models.UserInfo.objects.aggregate(k=Count('u_id', distinct=True), n=Count('nid')) ===> {'k': 3, 'n': 4} def count(self): # 获取个数 def get(self, *args, **kwargs): # 获取单个对象 def create(self, **kwargs): # 创建对象 def bulk_create(self, objs, batch_size=None): # 批量插入 # batch_size表示一次插入的个数 objs = [ models.DDD(name='r11'), models.DDD(name='r22') ] models.DDD.objects.bulk_create(objs, 10) def get_or_create(self, defaults=None, **kwargs): # 如果存在,则获取,否则,创建 # defaults 指定创建时,其他字段的值 obj, created = models.UserInfo.objects.get_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 2}) def update_or_create(self, defaults=None, **kwargs): # 如果存在,则更新,否则,创建 # defaults 指定创建时或更新时的其他字段 obj, created = models.UserInfo.objects.update_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 1}) def first(self): # 获取第一个 def last(self): # 获取最后一个 def in_bulk(self, id_list=None): # 根据主键ID进行查找 id_list = [11,21,31] models.DDD.objects.in_bulk(id_list) def delete(self): # 删除 def update(self, **kwargs): # 更新 def exists(self): # 是否有结果 ``` 8, Django 终端打印 SQL 语句 --------------------- * 在 Django 项目的 settings.py 文件中,在最后复制粘贴如下代码: ``` LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console':{ 'level':'DEBUG', 'class':'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level':'DEBUG', }, } } ``` * 即为你的 Django 项目配置上一个名为 django.db.backends 的 logger 实例即可查看翻译后的 SQL 语句。 9, 在 Python 脚本中调用 Django 环境 --------------------------- ``` import os if __name__ == '__main__': os.environ.setdefault("DJANGO_SETTINGS_MODULE", "BMS.settings") import django django.setup() from app01 import models books = models.Book.objects.all() print(books) ``` * **转自**:[https://www.cnblogs.com/liwenzhou/p/8660826.html](https://www.cnblogs.com/liwenzhou/p/8660826.html)
Jonny
2022年12月16日 23:01
363
0 条评论
转发
收藏文檔
上一篇
下一篇
手机扫码
複製鏈接
手机扫一扫转发分享
複製鏈接
如遇文档失效,可评论告知,便后续更新!
【腾讯云】2核2G云服务器新老同享 99元/年,续费同价
【阿里云】2核2G云服务器新老同享 99元/年,续费同价(不要✓自动续费)
【腾讯云】2核2G云服务器新老同享 99元/年,续费同价
【阿里云】2核2G云服务器新老同享 99元/年,续费同价(不要✓自动续费)
Markdown文件
Word文件
PDF文档
PDF文档(打印)
分享
鏈接
類型
密碼
更新密碼
有效期
